11 Diagramme : Cleveland Dot Plot

En cours de progression. Toute amélioration est la bienvenue. Si vous souhaitez participer rendez vous sur contribuer au repo.
11.1 Avant-propos
Cette section explique comment réaliser des Cleveland dot plots. Ces graphiques sont une bonne alternative à de simple bar chart, particulièrement si vous avez beaucoup d’éléments différents dans votre jeu de données. Pour que les légendes d’un bar chart se superposent c’est très rapide. Avec le même espace, beaucoup plus de valeurs peuvent être incluses dans un dot plot, et cela est de fait plus facile à lire. R possède une fonction de base dotchart(), mais comme il s’agit d’un graphe très simple le faire “from scratch” en base R ou en ggplot2 vous permet une plus grand personnalisation.
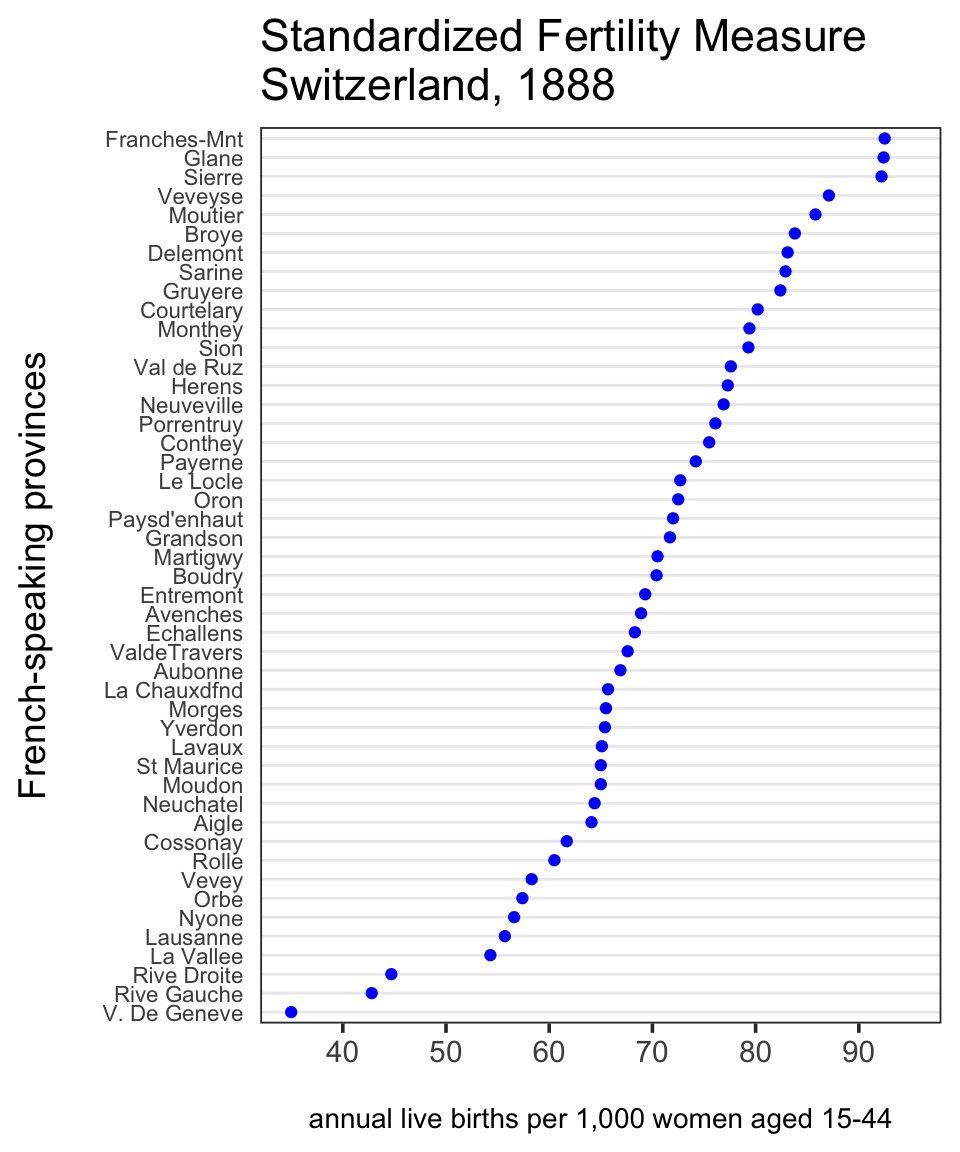
Le code :
library(tidyverse)
# create a theme for dot plots, which can be reused
theme_dotplot <- theme_bw(14) +
theme(axis.text.y = element_text(size = rel(.75)),
axis.ticks.y = element_blank(),
axis.title.x = element_text(size = rel(.75)),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_line(size = 0.5),
panel.grid.minor.x = element_blank())
# move row names to a dataframe column
df <- swiss %>% tibble::rownames_to_column("Province")
# create the plot
ggplot(df, aes(x = Fertility, y = reorder(Province, Fertility))) +
geom_point(color = "blue") +
scale_x_continuous(limits = c(35, 95),
breaks = seq(40, 90, 10)) +
theme_dotplot +
xlab("\nannual live births per 1,000 women aged 15-44") +
ylab("French-speaking provinces\n") +
ggtitle("Standardized Fertility Measure\nSwitzerland, 1888")11.2 Multiple dot plots
Pour cet exemple nous utiliseront les données de 2010 sur les scores moyens de staisfaction d’un échantillon des écoles publiques de NYC.
## Parsed with column specification:
## cols(
## DBN = col_character(),
## `School Name` = col_character(),
## `Number of Test Takers` = col_double(),
## `Critical Reading Mean` = col_double(),
## `Mathematics Mean` = col_double(),
## `Writing Mean` = col_double()
## )set.seed(5293)
tidydf <- df %>%
filter(!is.na(`Critical Reading Mean`)) %>%
sample_n(20) %>%
rename(Reading = "Critical Reading Mean", Math = "Mathematics Mean",
Writing = "Writing Mean") %>%
gather(key = "Test", value = "Mean", "Reading", "Math", "Writing")
ggplot(tidydf, aes(Mean, `School Name`, color = Test)) +
geom_point() +
ggtitle("Schools are sorted alphabetically", sub = "not the best option") + ylab("") +
theme_dotplot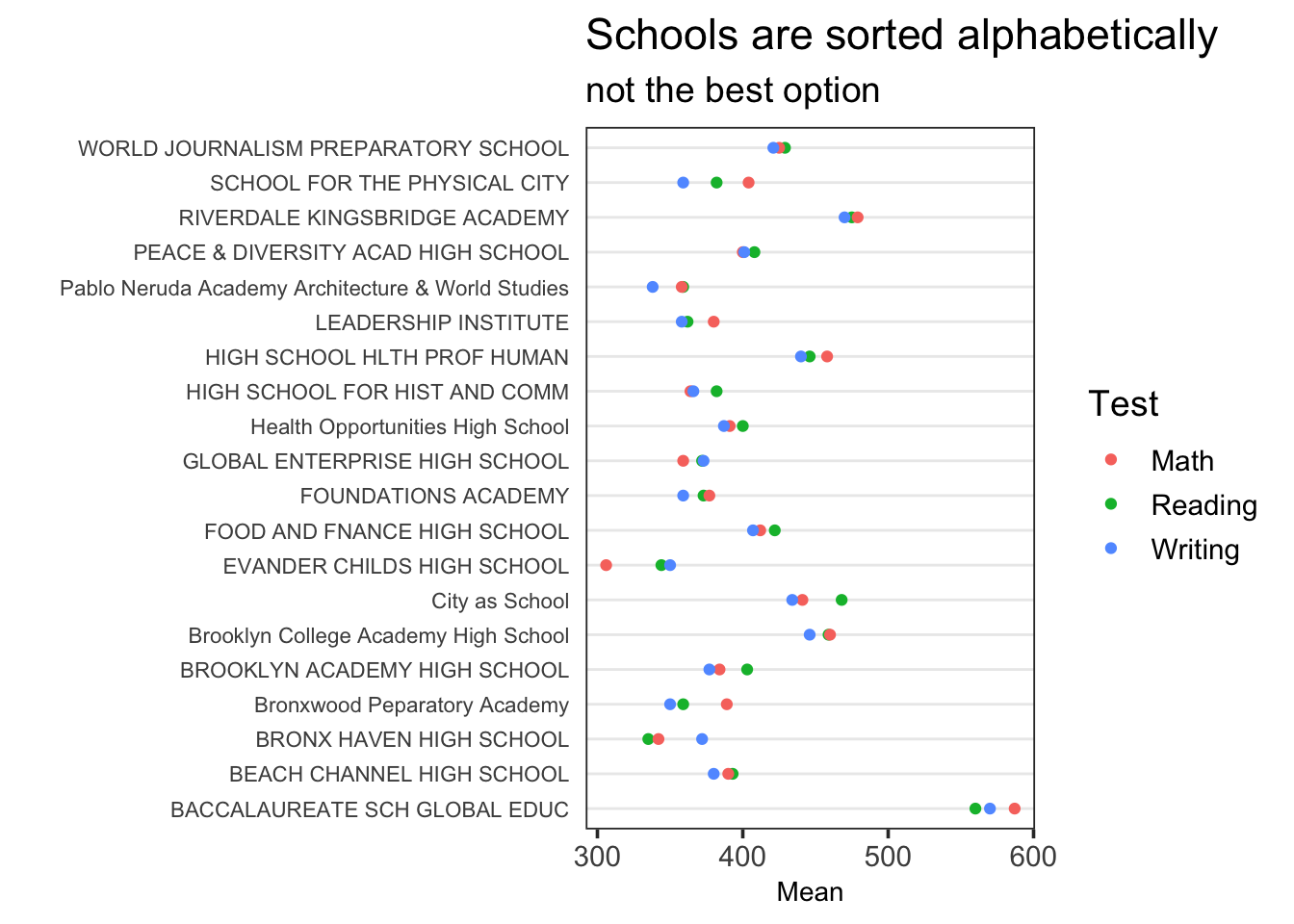
Notez que School Name est trié par niveau de facteur, qui par défaut est en ordre alphabétique. Un meilleur choix est de trier par un des niveau de Test. C’est généralement la meilleur façon pour trier des facteurs et mettre en évidence des motifs.
Pour réaliser un double tri de School Name par Test et ensuite Mean, on utilise forcats::fct_reorder2(). Cette fonction trie .f (un facteur ou un vecteur de caractères) en triant deux vecteurs .x et .y. Pour ce type de graphique, .x est la variable représentée par les points de couleurs et .y est la variable continues tracée sur l’axe des y.
Supposons que nous voulons trier les écoles par score de lecture moyen. On peut le faire en limitant la variable Test à “Reading” lorsque l’on trie sur Mean :
ggplot(tidydf,
aes(Mean, fct_reorder2(`School Name`, Test=="Reading", Mean, .desc = FALSE),
color = Test)) +
geom_point() + ggtitle("Schools sorted by Reading mean") + ylab("") +
theme_dotplot 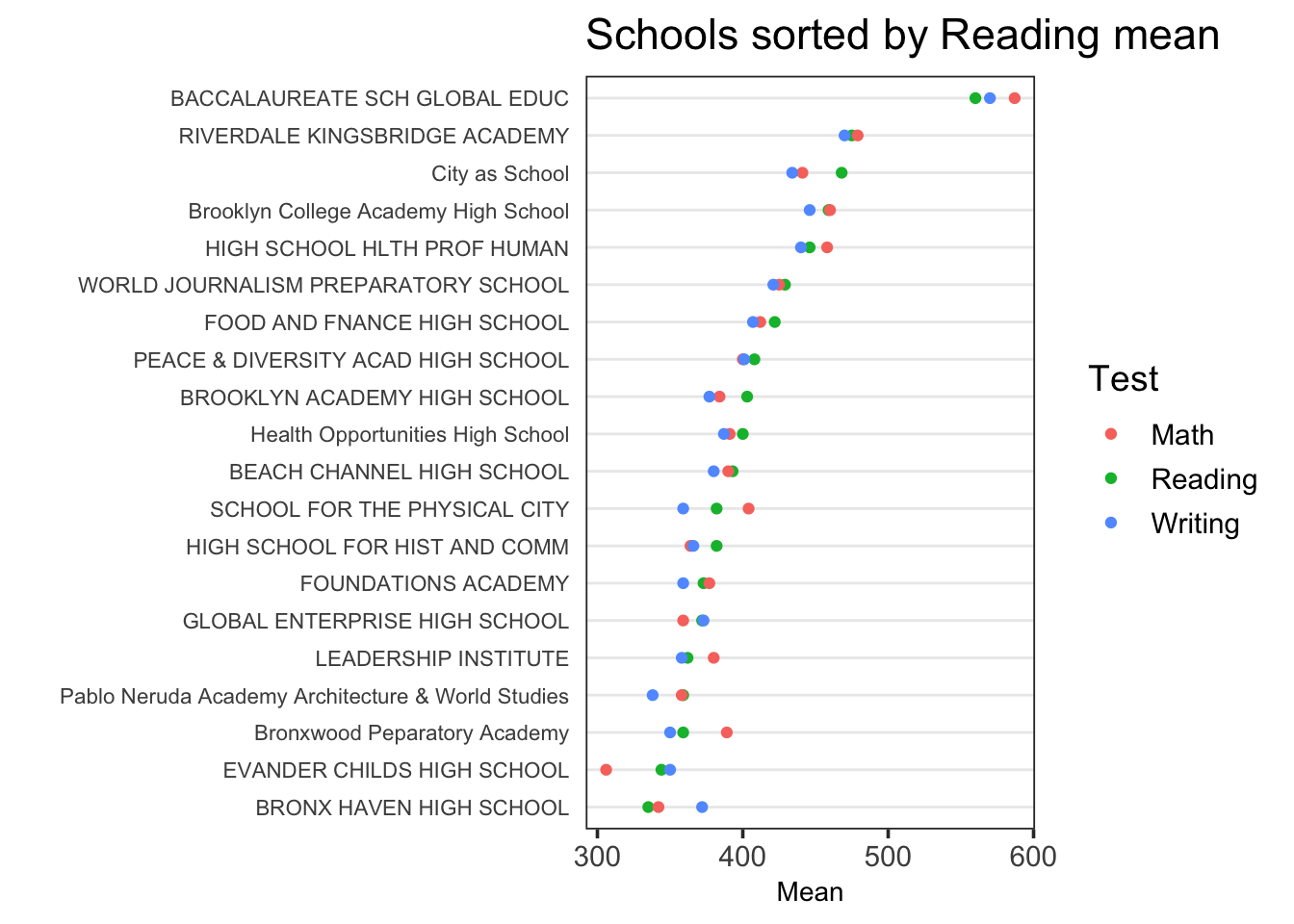
(Un grand merci à Zeyu Qiu pour le conseil sir comment régler .x directement en niveau de facteur, une meilleure approche que le réordonnement de facteurs pour s’adapter à fct_reorder2(), comme mentionné plus haut).
Bien qu’il s’agisse d’une méthode directe, il y aura peut-être des cas où il sera plus facile de préciser que vous voulez trier par rapport au premier ou au dernier facteur de la variable Test sans l’expliciter.
Si un niveau de facteur n’est pas spécifier, par défaut fct_reorder2() triera par rapport au dernier facteur de .x. Dans notre cas, “Writing” est le dernier facteur de Test :
ggplot(tidydf,
aes(Mean, fct_reorder2(`School Name`, Test, Mean, .desc = FALSE),
color = Test)) +
geom_point() + ggtitle("Schools sorted by Writing mean") + ylab("") +
theme_dotplot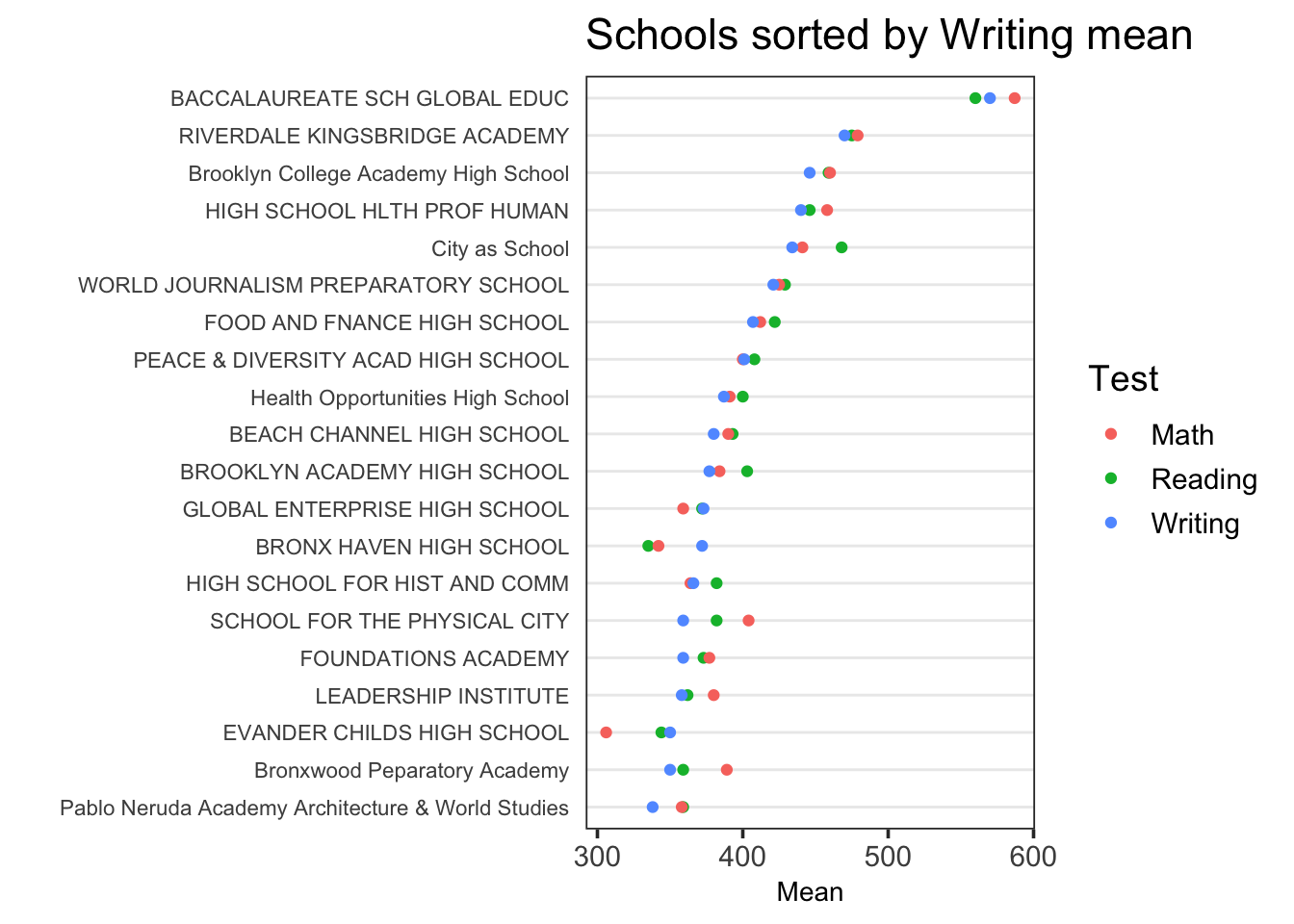
Si vous voulez trier par rapport au premier facteur de .x, “Math” dans notre cas, vous aurez besoin de la version dev de forcats que vous pouvez installer via :
devtools::install_github("tidyverse/forcats")
Changer la fonction de trie par défaut last2()par first2() :
ggplot(tidydf,
aes(Mean, fct_reorder2(`School Name`, Test, Mean, .fun = first2, .desc = FALSE),
color = Test)) +
geom_point() + ggtitle("Schools sorted by Math mean") + ylab("") +
theme_dotplot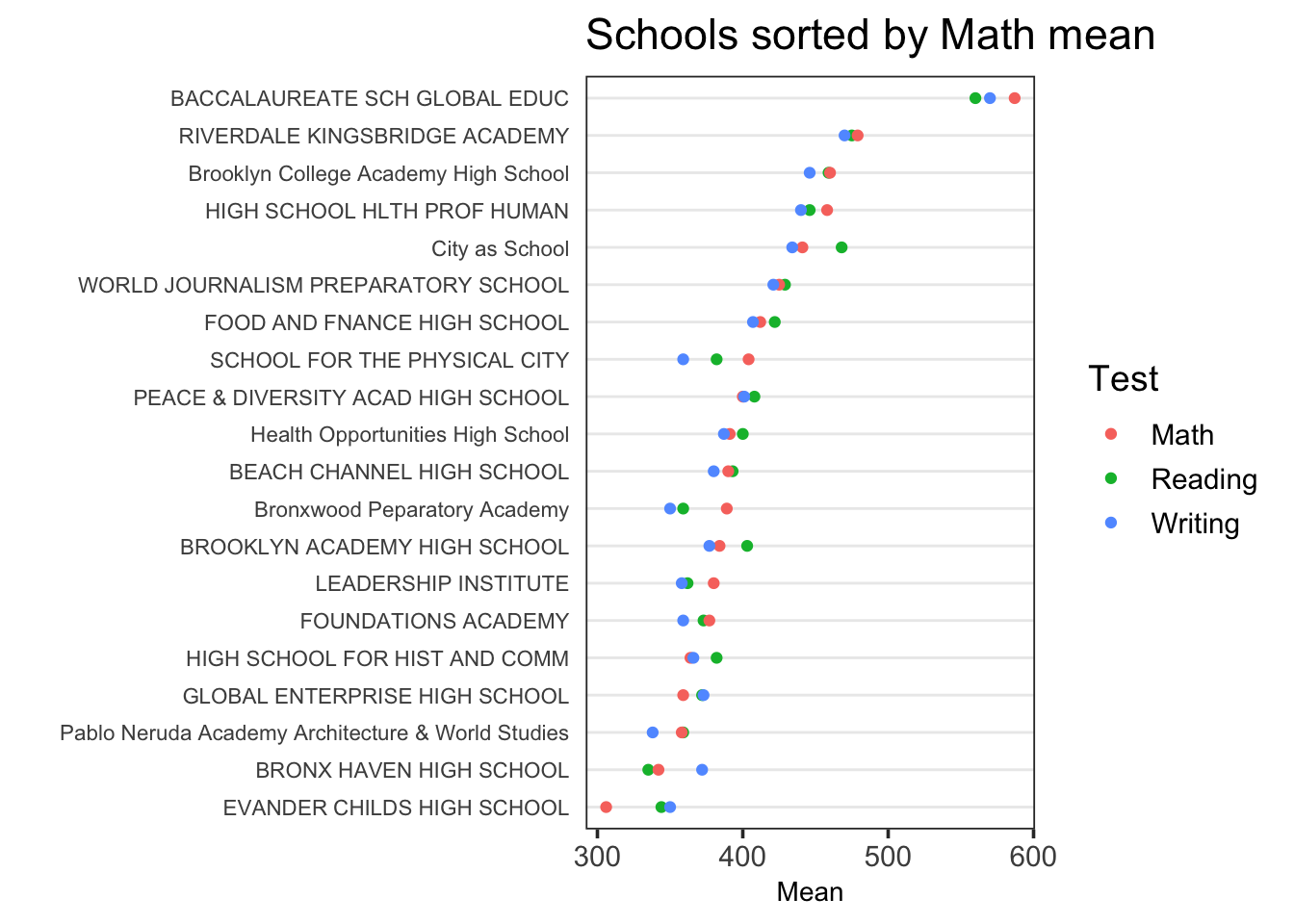
with