13 Walkthrough: Iris Scatterplot

13.1 Avant-propos
Cet exemple s’intéresse au jeu de données iris et s’achève par la construction d’un scatterplot présentable.
13.1.1 tl;dr
Voilà ce à quoi on doit aboutir :
library(ggplot2)
base_plot <- ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), size = 3, alpha = 0.5, position = "jitter") +
xlab("Sepal Length (cm)") +
ylab("Sepal Width (cm)") +
ggtitle("Sepal Dimensions in Different Species of Iris Flowers")
base_plot + theme_minimal()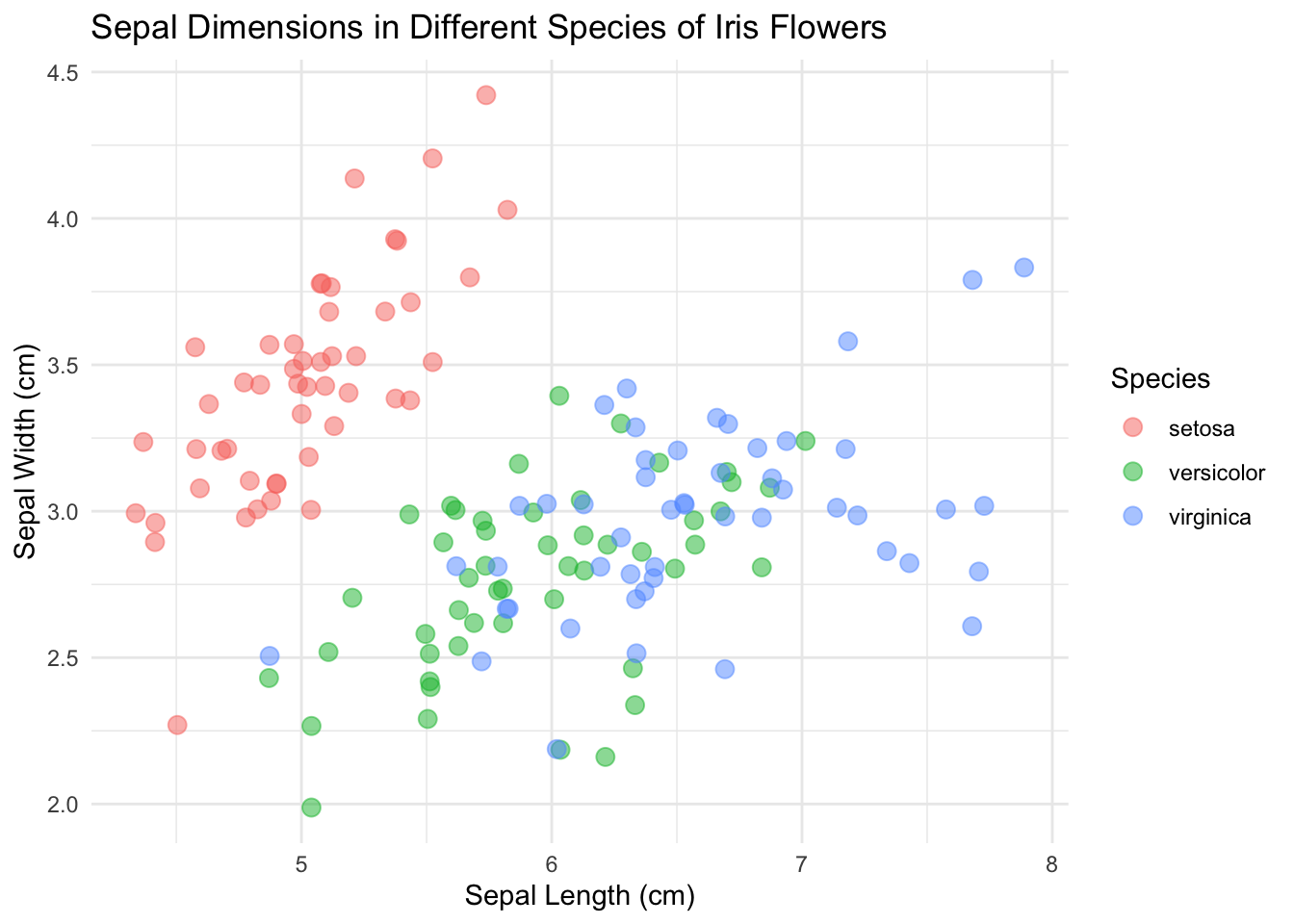
Tu te demandes comment on est arrivé là ? Tu peux jeter un oeil à
13.1.3 Techniques
On te les laisse en anglais par cohérence avec le cours et les recherches que tu pourras faire sur Google
- Keyboard Shortcuts
- Viewing Data Structure/Dimensions/etc.
- Accessing Documentation
- Plotting with
ggplot2 - Layered Nature of
ggplot2/Grammar of Graphics - Mapping aesthetics in
ggplot2 - Overlapping Data: alpha and jitter
- Presenting Graphics
- Themes
13.2 Petite note sur comment le faire sans effort
Les raccourcis sont tes meilleurs amis pour aller plus vite. Et en plus ils sont faciles à trouver.
Dans la barre principale :
Tools > Keyboard Shortcuts Help OR ⌥⇧K
Quelques bons raccourcis :
- Insérer un opérateur d’assignation (
<-): Alt/Option+- - Insérer un (
%>%): Ctrl/Cmd+Shift+M - Mettre un commentaire : Ctrl/Cmd+Shift+C
- Lancer la ligne ou la sélection : Ctrl/Cmd+Enter
- Relancer la cellule d’avant : Ctrl/Cmd+Shift+P
Restez attentif à chose que vous faites tout le temps et demander vous si vous ne pourriez pas le faire plus rapidement.
En outre, l’IDE RStudio peut se montrer intimidant, mais il est rempli de petits outils que vous pourrez lire sur cette cheatsheet ou bien sur un des cours de DataCamp : Part 1, Part 2.
Okay, maintenant on est parti…
13.3 Visualisation des données
Commençons par charger le package, ainsi on pourra récupérer les données dans un dataframe.
## [1] "data.frame"Ce n’est pas un très grand jeu de données, mais c’est utile de prendre l’habitude de considérer un jeu de données comme lourd quoi qu’il arrive. Par conséquent avant d’afficher le jeu de données dans le terminal soyez certain d’avoir regarder la taille et la structure de données de votre jeu de données.
Ici on peut voir qu’on a 150 observations sur 5 variables différentes.
## [1] 150 5Il y a plein de façon d’avoir les infos sur votre jeu de données, en voici quelques uns :
## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## ## Observations: 150
## Variables: 5
## $ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5…
## $ Sepal.Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3…
## $ Petal.Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5, 1.4, 1.5, 1…
## $ Petal.Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.1, 0…
## $ Species <fct> setosa, setosa, setosa, setosa, setosa, setosa, set…Afficher les données en appelant iris dans le terminal affichera la totalité. Allez-y dans ce cas précis vous pouvez essayer, mais ce n’est pas recommendé pour les jeux de données plus large. Au contraire vous pouvez utiliser head() ou bien View() dans le terminal.
Si vous souhaitez en apprendre plus sur une commande, tapez juste ?<command> dans le terminal. Par exemple ?head vous apprendra que la fonction head dispose d’un argument supplémentaire n pour le nombre de lignes que vous souhaitez afficher (par défaut égal à 6). Aussi remarquerez vous peut-être qu’il y a quelque chose appelé tail. Je me demande à quoi ça sert !
13.4 Afficher les données
Affichons quelque chose !
![]()
Où est-ce que c’est ? Peut-être que si nous ajoutons quelques aesthetics… Je me rappelle avoir entendu ce mot important quelque part :
![]()
Toujours rien. Rappelez-vous que qu’il faut ajouter une geom pour afficher quelque chose.
Houra ! Quelque chose s’est affiché ! Faites attention à où nous avons mis les données, à l’intérieur de ggplot(). ggplot est composé de couches et ici nous avons mis les données dans la fonction principale de ggplot. L’argument data est aussi disponible dans geom_point(), mais cela ne s’appliquera qu’à cette couche précise. Ici nous avons fixé que sans précisions supplémentaire l’argument data sera iris.
Maintenant ajoutons un peu de couleur par Species :
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species))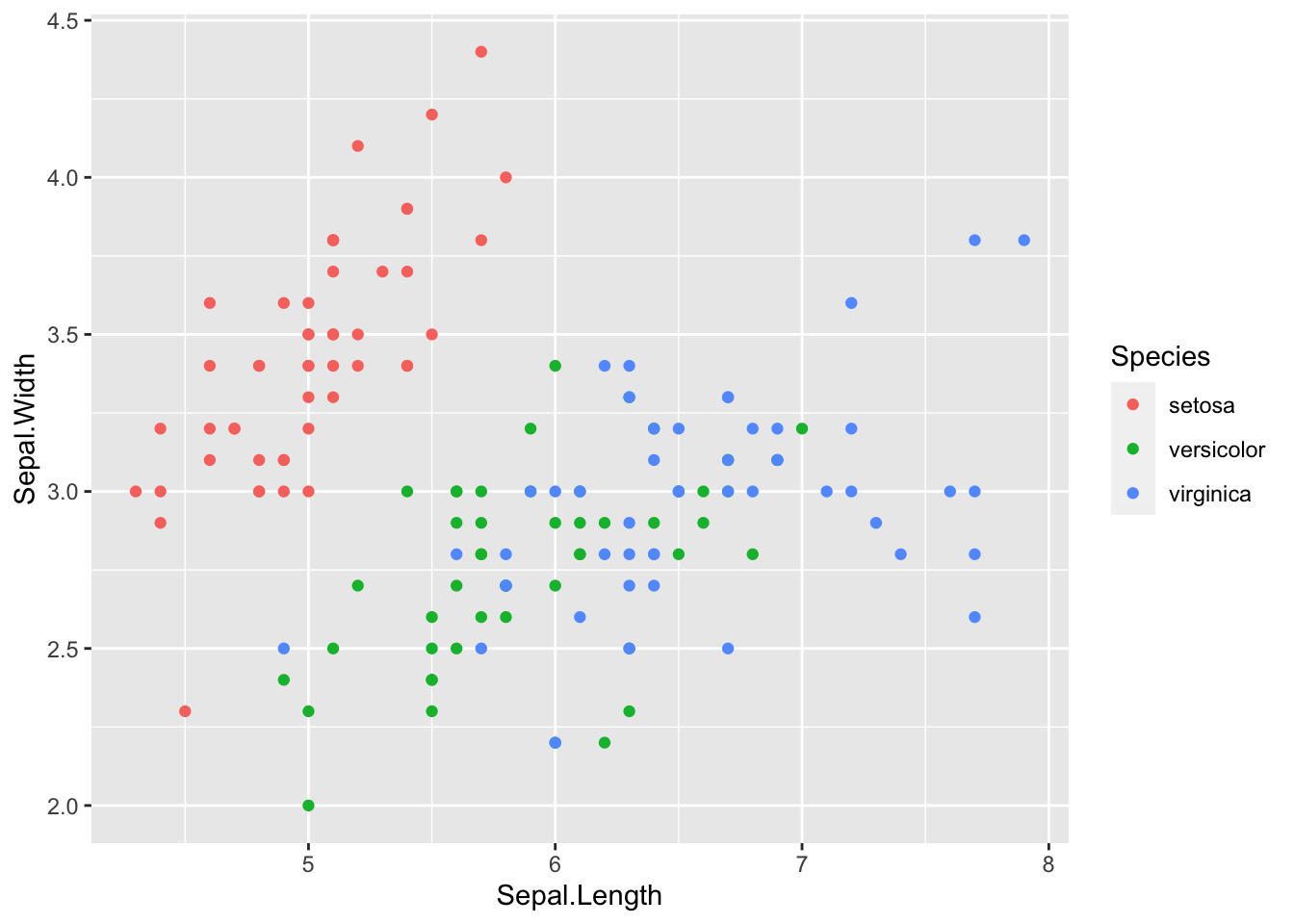
Générallement c’est utile de stocker la majeure partie du graphique dans une variable et ensuite d’y ajouter des couches. Le code ci-dessous réalise le même travail qu’au dessus :
13.5 Markdown etiquette
Je remarque que mon fichier R Markdown est un peu en bazar. On peut rapidement perdre le controle d’un fichier Rmd mais ils y a quelques astuces pour ça. La première chose, donnez des noms à vos chunks. Si en plus vous combinez ça avec des entêtes le travaille sera mieux organisé. Plus particulièrement la petite ligne en bas de l’éditeur à toute son utilité.
De ça :
A ça :
Ajoutez un nom au début de chaque chunk :
{r <cool-code-chunk-name>, <chunk_option> = TRUE}
Maintenant on est capable de savoir de quoi parle la chunk et où on en est dans le document. N’oubliez pas, il faut un espace après le r et une virgule entre chaque option telle que eval ou echo. Pour plus d’info voir notre section pour communique des résultats.
13.6 Chevauchement de données
Ceux qui ont un compas dans l’oeil auront remarqué mais quelques points ont disparus. On devrait avoir 150 points, pour autant on en voit que 117 (oui oui je les ai compté). Où sont passés les 33 points manquants ? En fait, ils sont cachés derrières d’autres points. Le jeu de données arrondi au dixième de centimètre prêt ce qui nous donne ce placement des points si régulier. Comment je sais que c’est en centimètres ? J’ai fait ?iris dans le terminal mon cher Watson ! Ah, question bête, réponse bête.
# This plot hides some of the points
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species))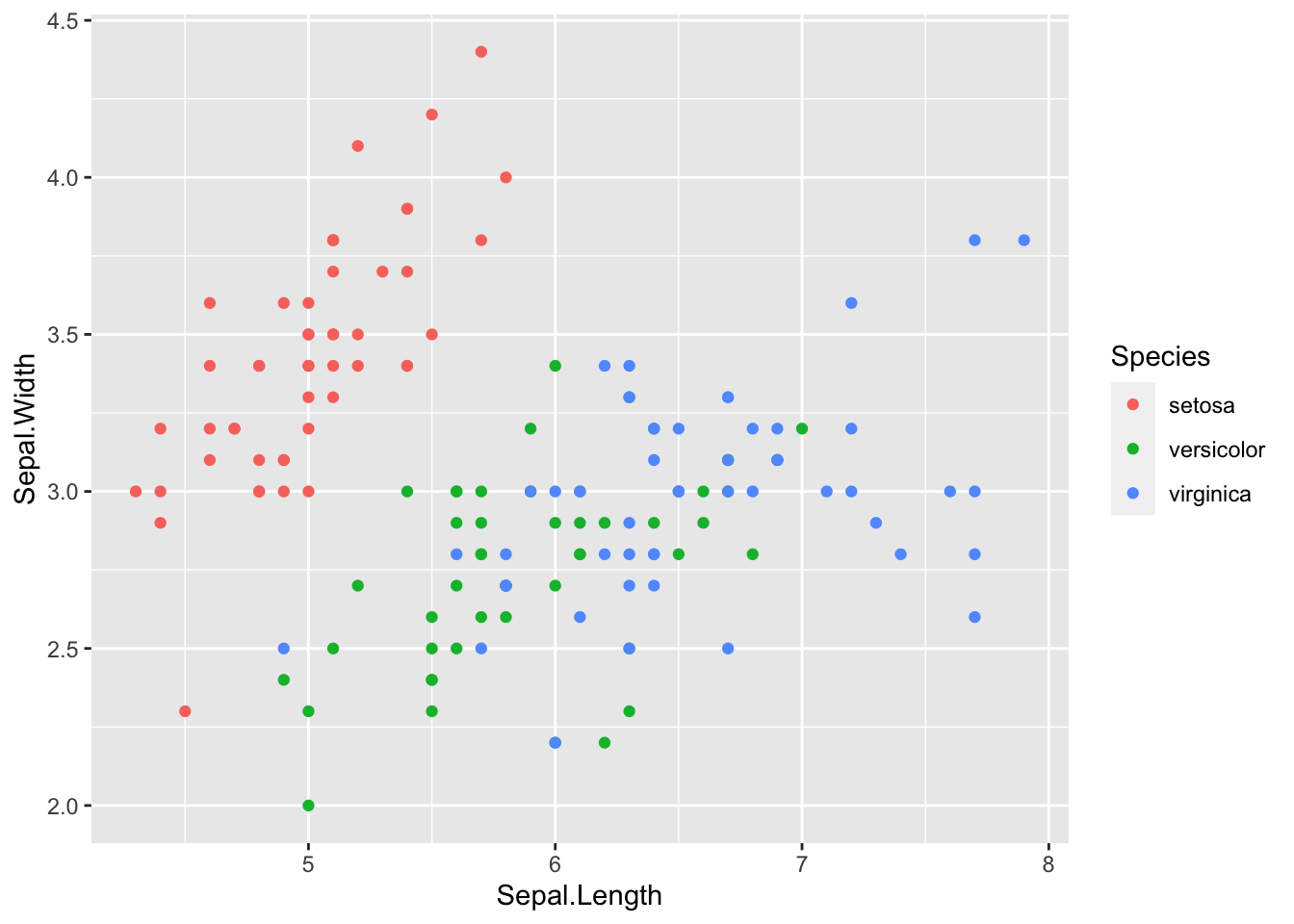
Qui est le coupable ? L’aesthetic color. La couleur par défaut est opaque et cachera tous les points qui sont derrière. En règle générale c’est toujours bénéfique de réduire l’opacité un petit peu pour éviter ce problème. Pour faire ça changer la valeur de alpha pour quelque chose différent de 1, par exemple 0.5.
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species, alpha = 0.5))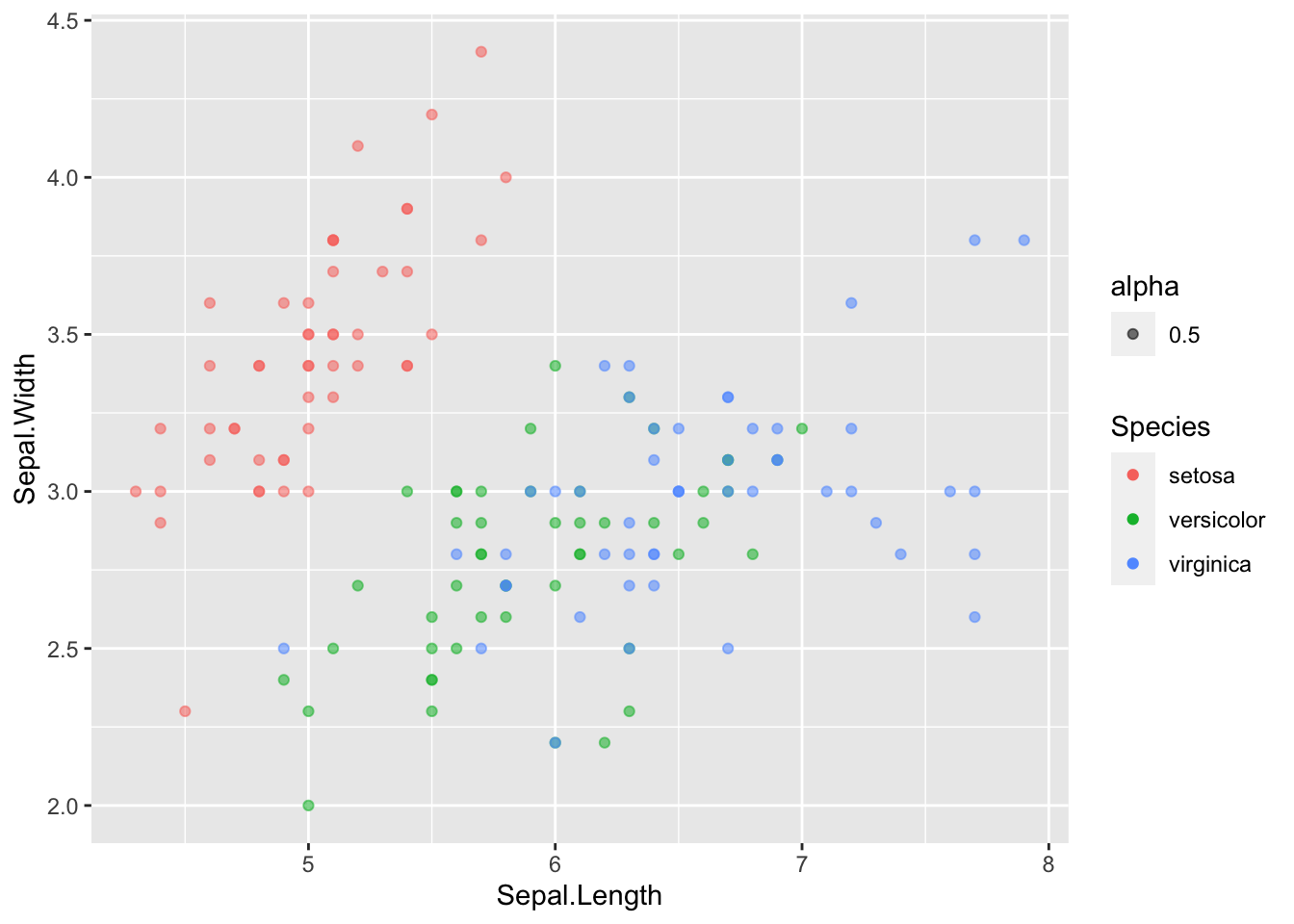
Okay… Plusieurs choses.
13.6.1 Premièrement : la légende
Premièrement, avez-vous remarqué l’ajout soudain de la légende ? C’est idiot ! Pourquoi c’est apparu comme ça ? En fait, lorsqu’on a ajouté alpha dans aes() cela a généré une légende. Regardons plus en détail geom_point(). Plus particulièrement cela nous montre où on doit préciser color et alpha :
geom_point(mapping = aes(color = Species, alpha = 0.5))
Donc on associe ces aesthtics color and alpha, à certains valeurs. ggplot sait que généralement cette association va varier étant donné que vous êtes en train de travailler sur des données qui elles-mêmes varient. C’est pourquoi il va créer une légende pour chaque association. Néanmoins pour le alpha on a pas besoin de légende on l’a fixé à 0.5. Si on veut changer ça, il suffit de mettre alpha à l’exterieur de l’aes et le traiter comme un argument :
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), alpha = 0.5)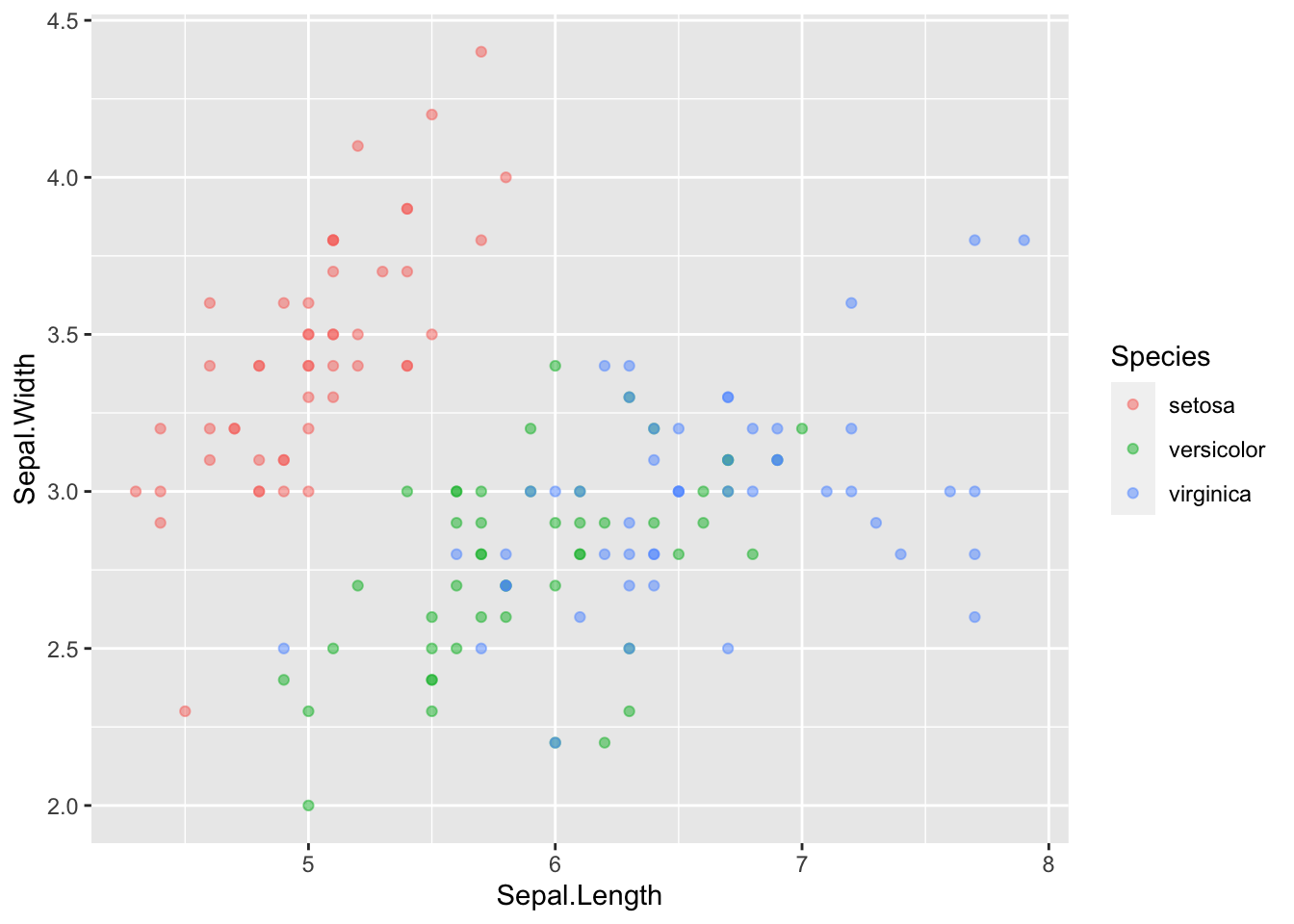
Plus de légende. Donc sur ggplot on obtient pas le même résultat suivant où est placé l’aesthetic. C’est ce qu’on appelle le MAPPING d’aesthetic (faire varier avec des données à l’intérieur de aes) ou le SETTING d’aesthetic (le rendre constant sur tous les points en plaçant le paramètre à l’éxterieur de aes).
13.6.2 Deuxièment : le jittering
Deuxièment, est-ce que l’astuce du alpha nous a vraiment aidé ? Est-ce qu’on est capable de véritablement voir les choses plus facilement ? Pas vraiment… Comme les points se chevauche parfaitement, l’opacité ne nous aide pas tant que ça. Habituellement l’opacité marche mais ici les données sont si régulières que ça n’améliore pas leur perception.
On peut régler ça en ajoutant du jitter au points. Le Jitter ajoute un bruit aléatoire aux points et les bougent de sorte qu’ils ne se chevauchent plus entièrement :
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), alpha = 0.5, position = "jitter")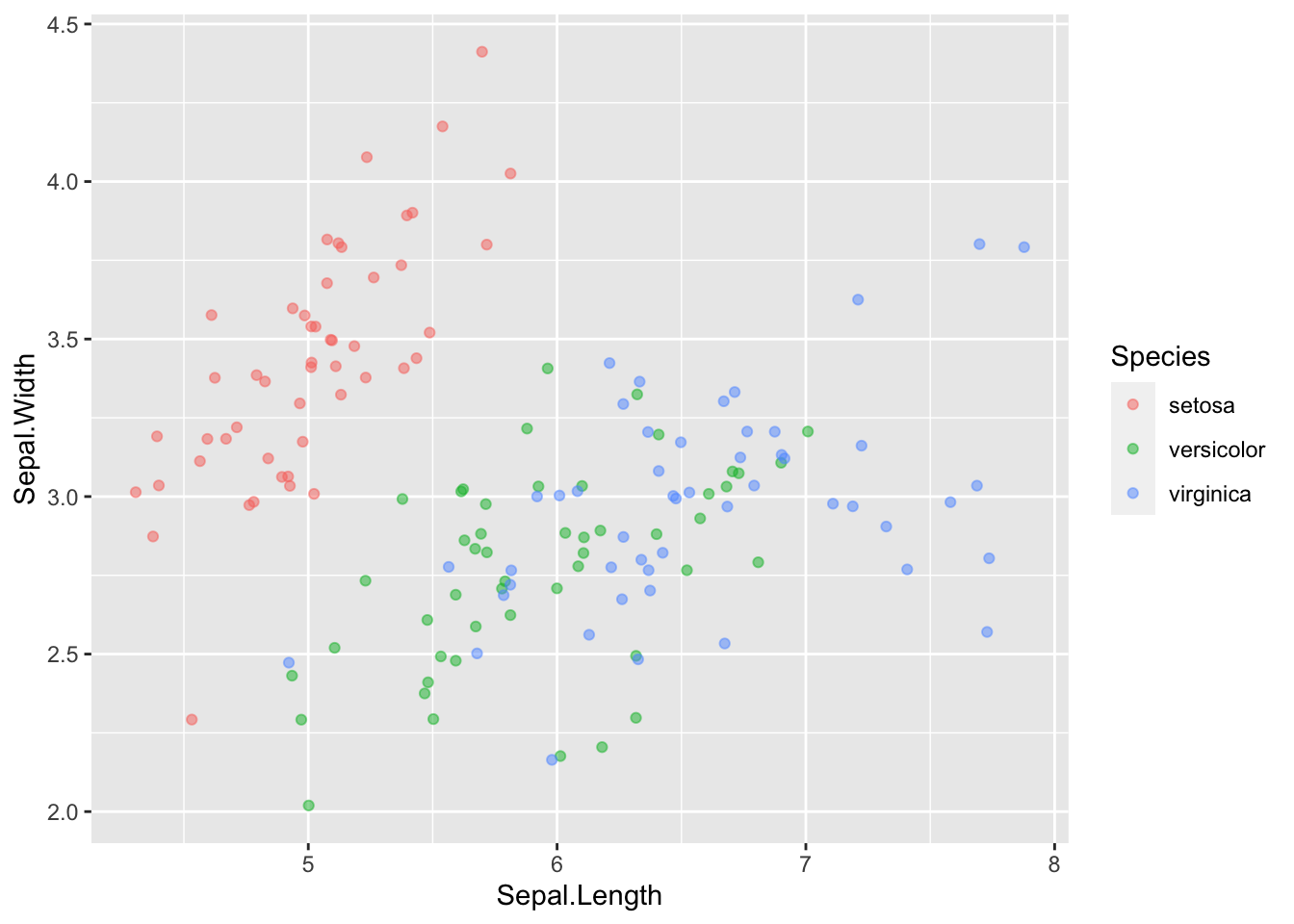
Utilisez le jittering avec modération et n’oubliez pas que vous altérer les données. Néanmoins dans certaines situations c’est très utile.
13.6.3 Parenthèse : Exemple de cas où le alpha blending est utile
Nous avons vu un cas où le jittering marchait très bien, alors que le alpha ne nous aidait pas plus que ça. Voyons maintenant un exemple où l’opacité et le changement du alpha sera directement utile.
# lib for arranging plots side by side
library(gridExtra)
# make some normally distributed data
x_points <- rnorm(n = 10000, mean = 0, sd = 2)
y_points <- rnorm(n = 10000, mean = 6, sd = 2)
df <- data.frame(x_points, y_points)
# plot with/without changed alpha
plt1 <- ggplot(df, aes(x_points, y_points)) +
geom_point() +
ggtitle("Before (alpha = 1)")
plt2 <- ggplot(df, aes(x_points, y_points)) +
geom_point(alpha = 0.1) +
ggtitle("After (alpha = 0.1)")
# arrange plots
gridExtra::grid.arrange(plt1, plt2,
ncol = 2, nrow = 1)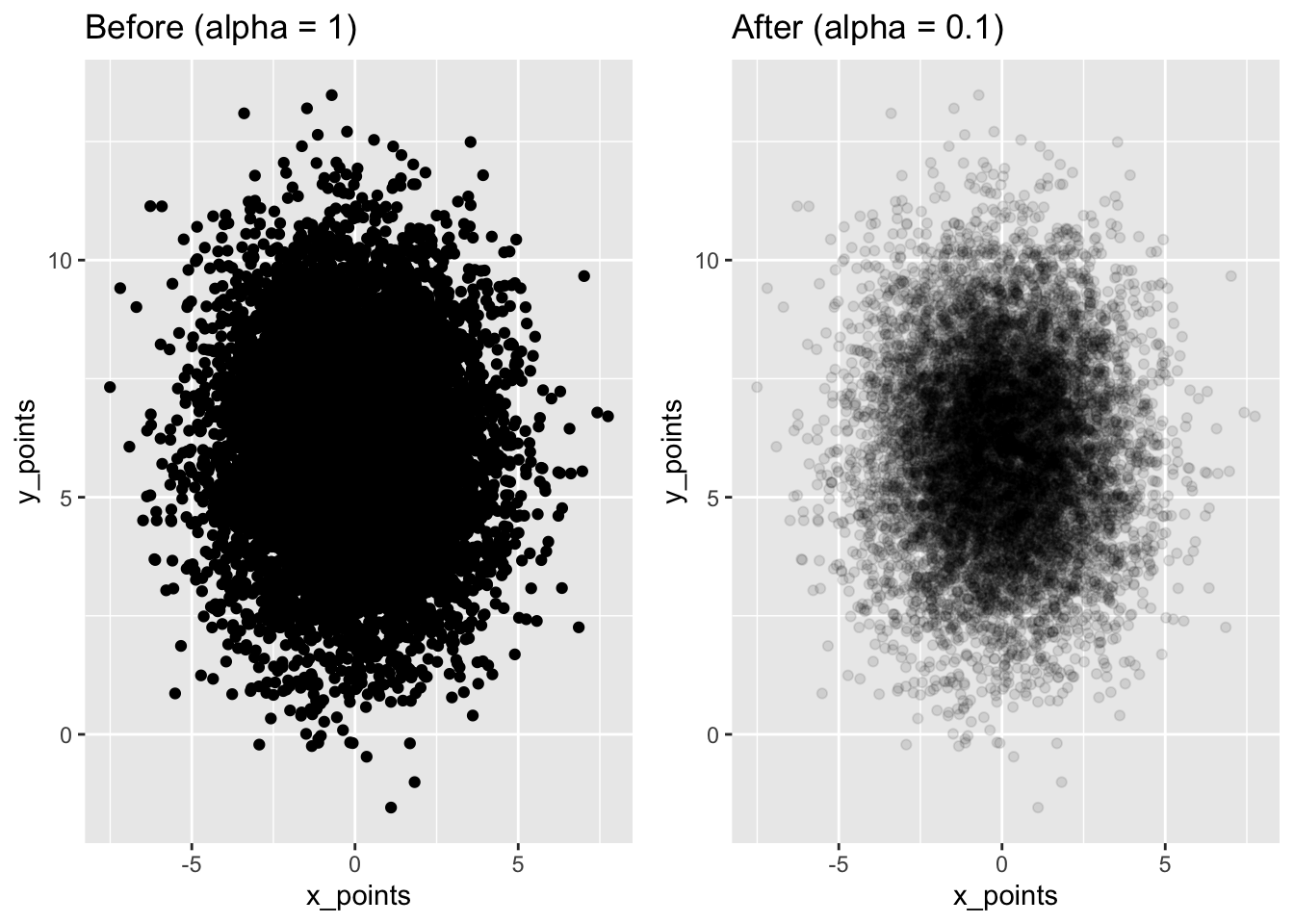
Ici, c’est plus simple de voir que le jeu de données est très concentré.
13.7 Remanier pour présenter
Disons que nous avons fini notre graphique et que nous sommes prêt à le présenter à d’autres gens :
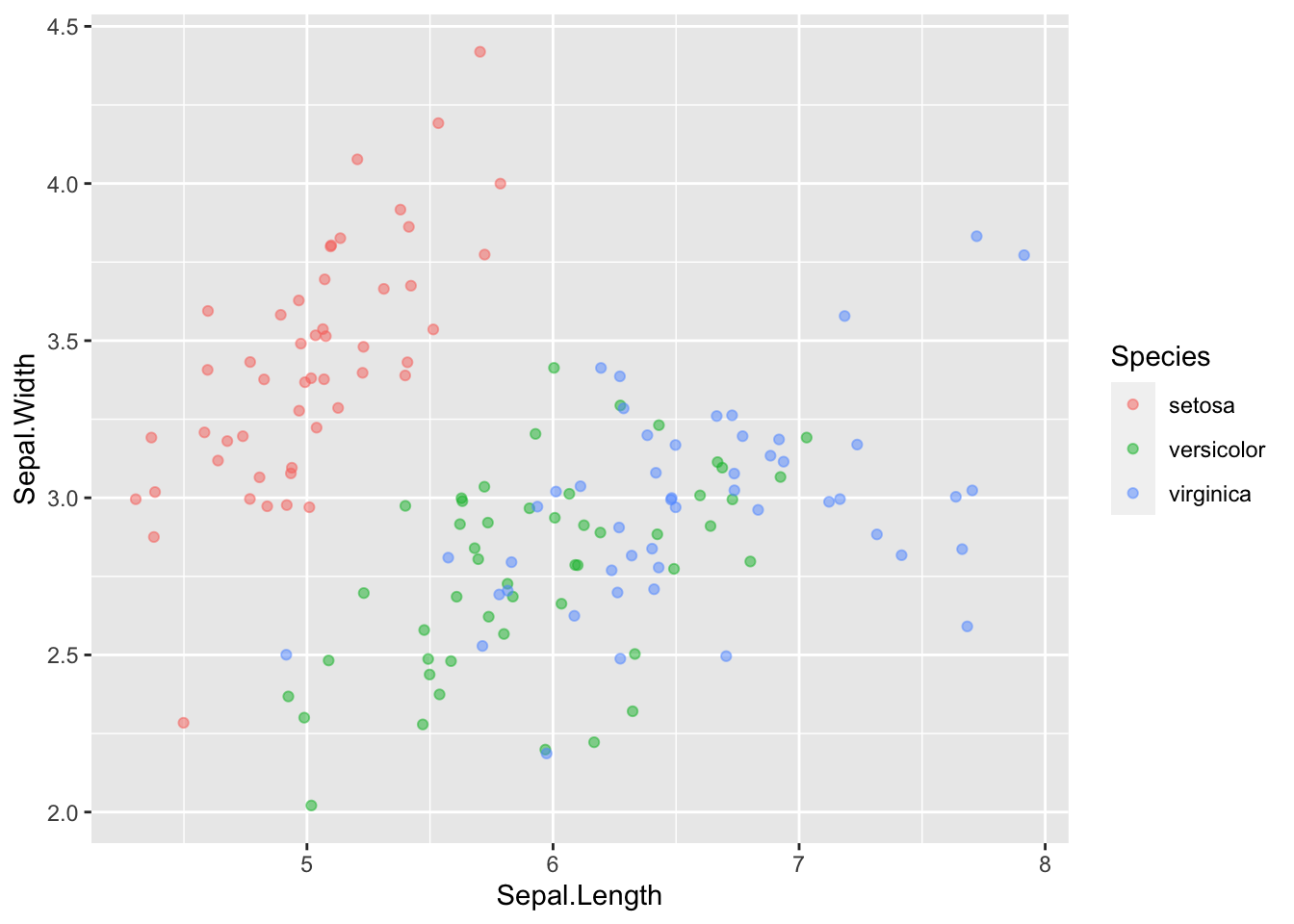
We should clean it up a bit so it can stand on its own.
13.8 Modifier l’apparence
Premièrement, rendons les noms des axes x/y plus clairs et descriptifs :
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), alpha = 0.5, position = "jitter") +
xlab("Sepal Length (cm)") +
ylab("Sepal Width (cm)")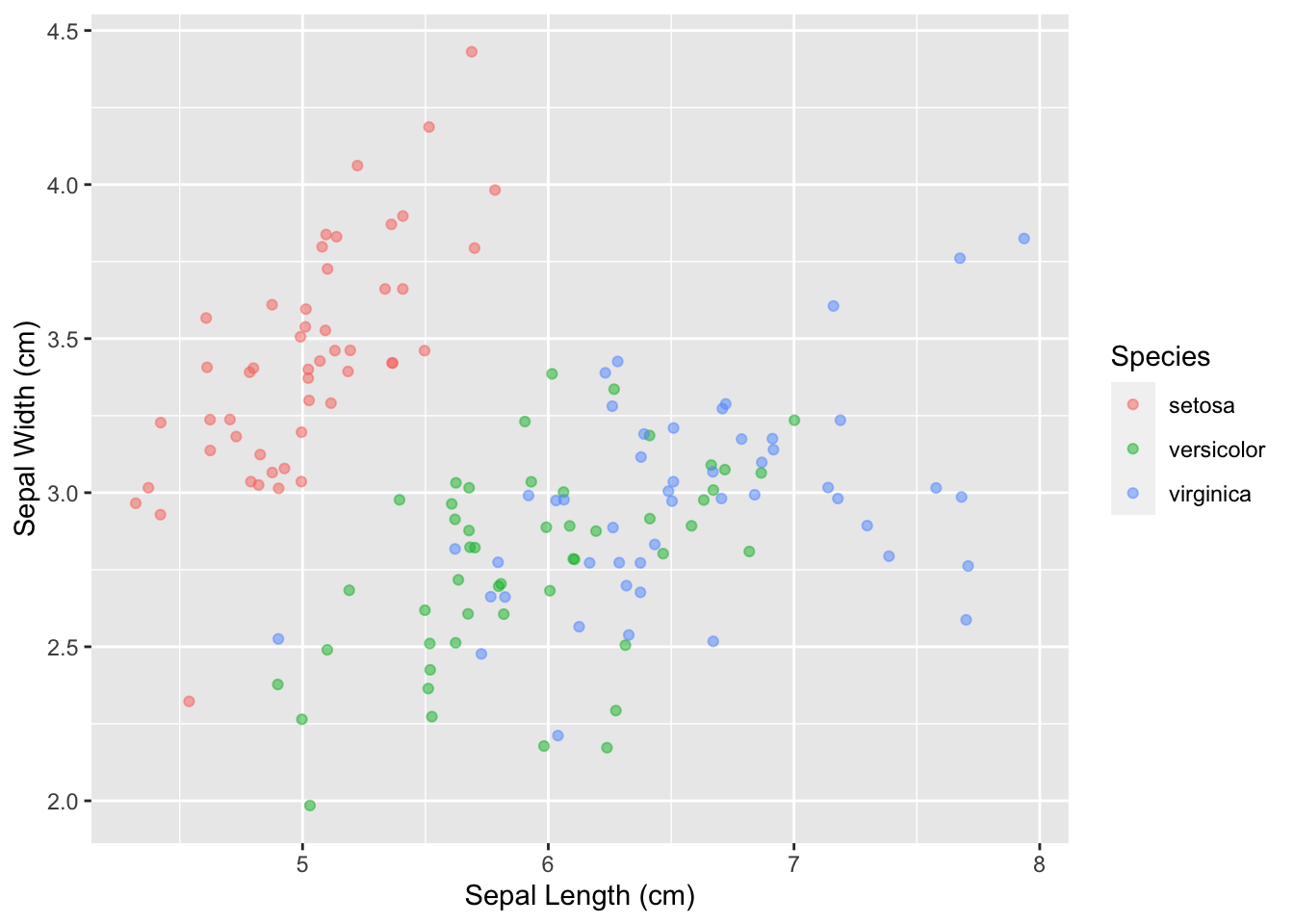
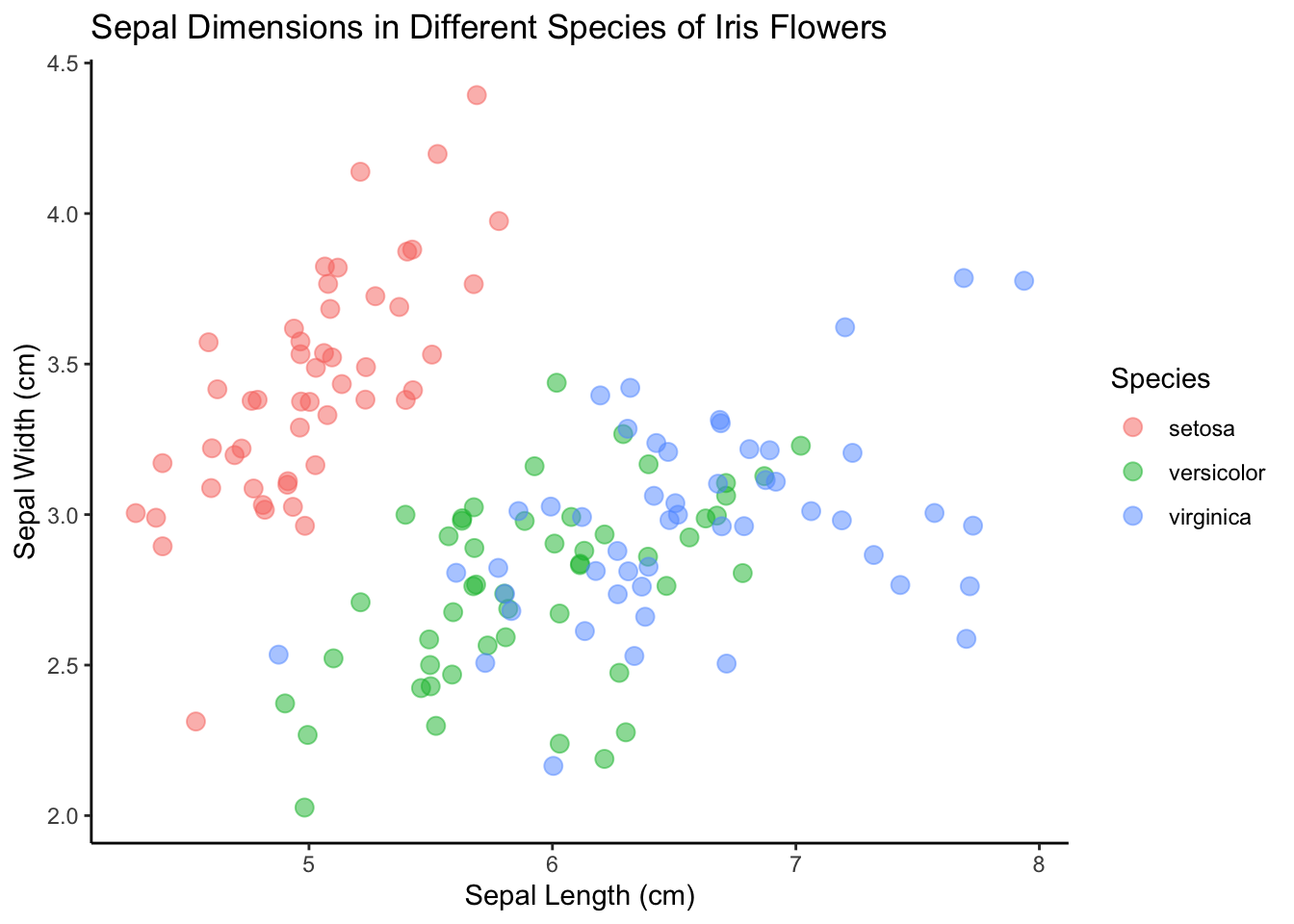
Ensuite, mettons un titre :
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), alpha = 0.5, position = "jitter") +
xlab("Sepal Length (cm)") +
ylab("Sepal Width (cm)") +
ggtitle("Sepal Dimensions in Different Species of Iris Flowers")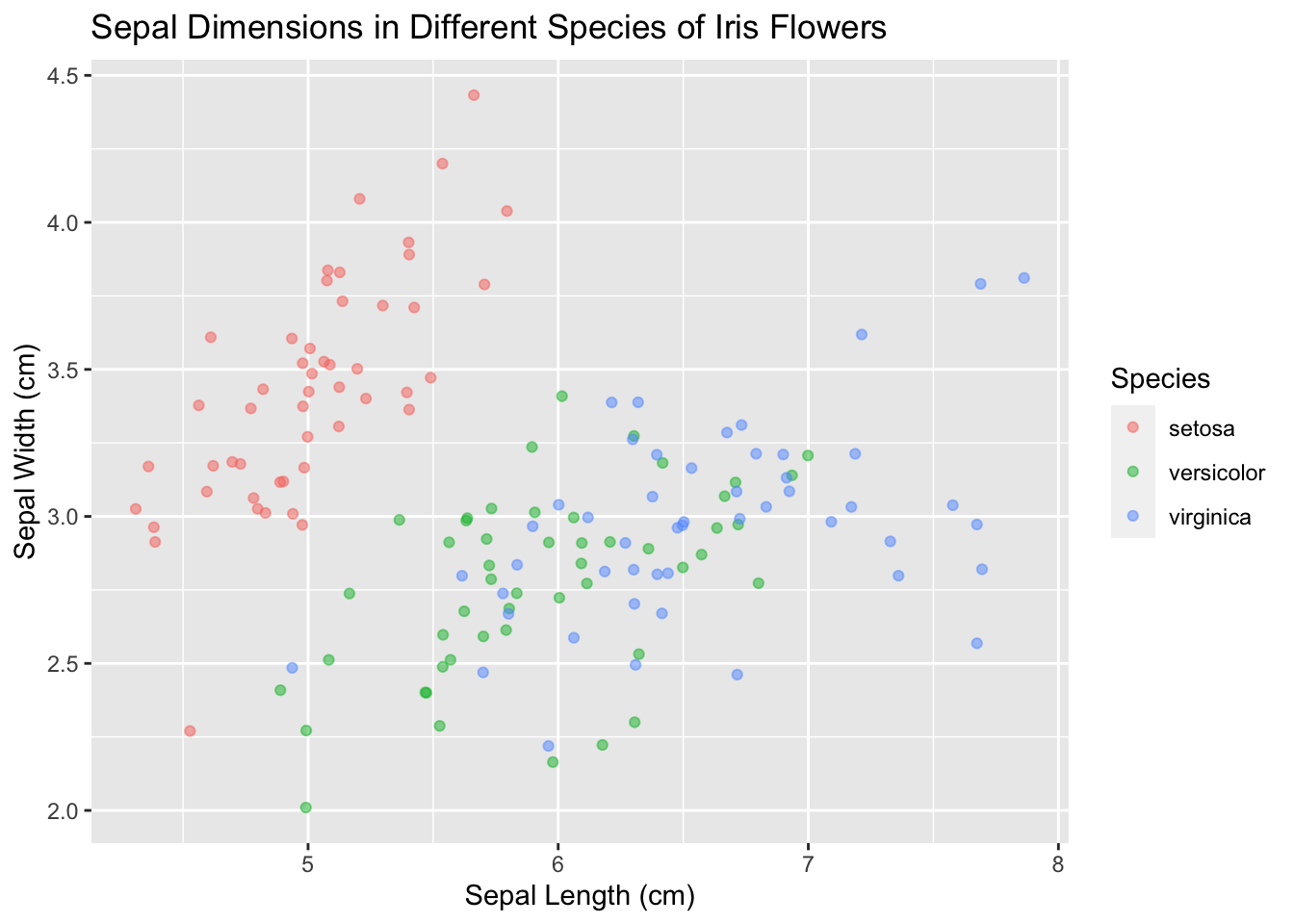
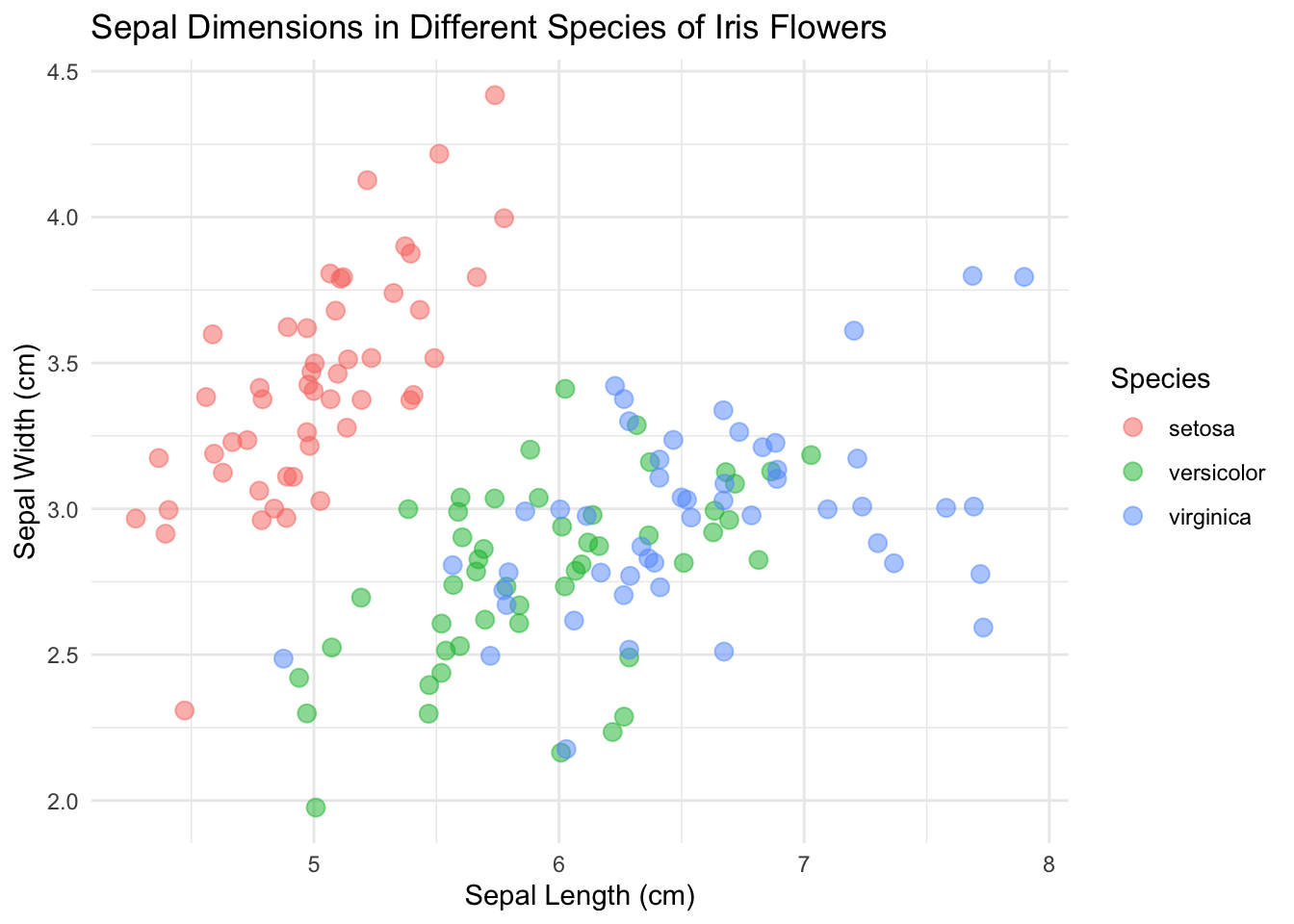
Et grossissons les point :
ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), size = 3, alpha = 0.5, position = "jitter") +
xlab("Sepal Length (cm)") +
ylab("Sepal Width (cm)") +
ggtitle("Sepal Dimensions in Different Species of Iris Flowers")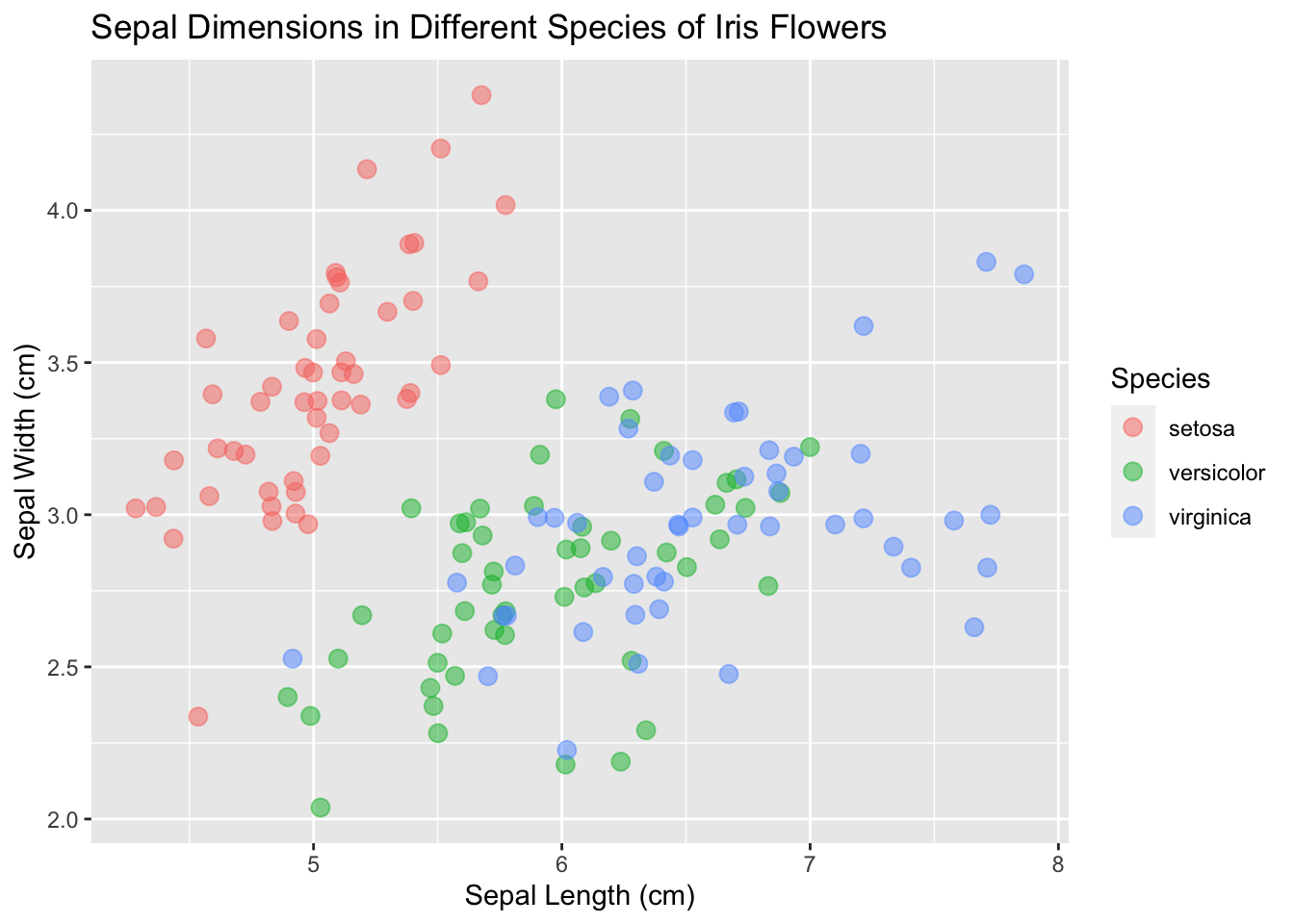
Maintenant c’est présentable !
13.9 Ajouter des themes
Il sera dans certaine situation mieux de changer les theme de votre graphique (l’arrière-plan, les axes, “accessories” etc.). Jetez un oeil aux différents thèmes qui existent et choisissez en un qui vous plait.
base_plot <- ggplot(data = iris, mapping = aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species), size = 3, alpha = 0.5, position = "jitter") +
xlab("Sepal Length (cm)") +
ylab("Sepal Width (cm)") +
ggtitle("Sepal Dimensions in Different Species of Iris Flowers")
base_plot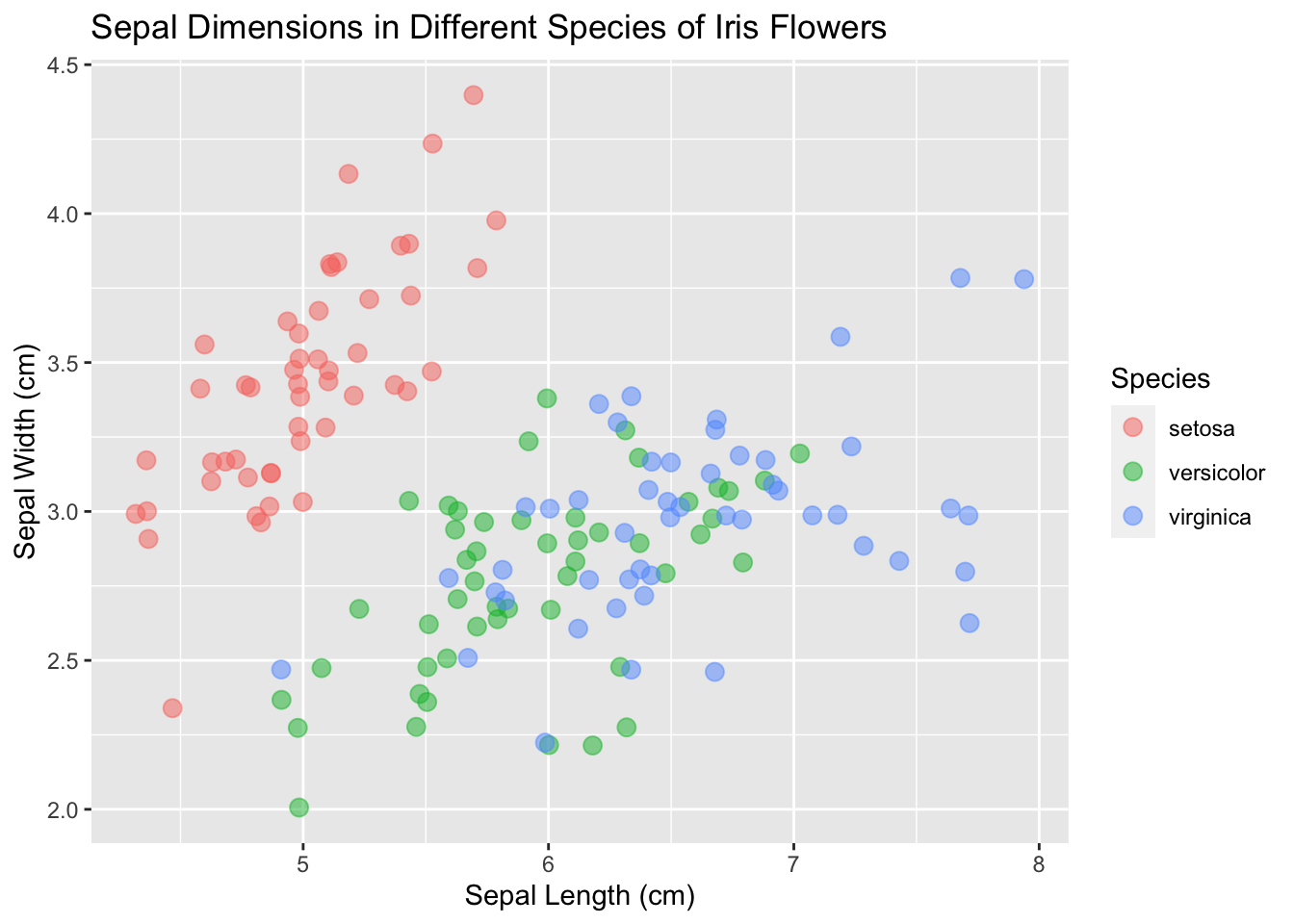
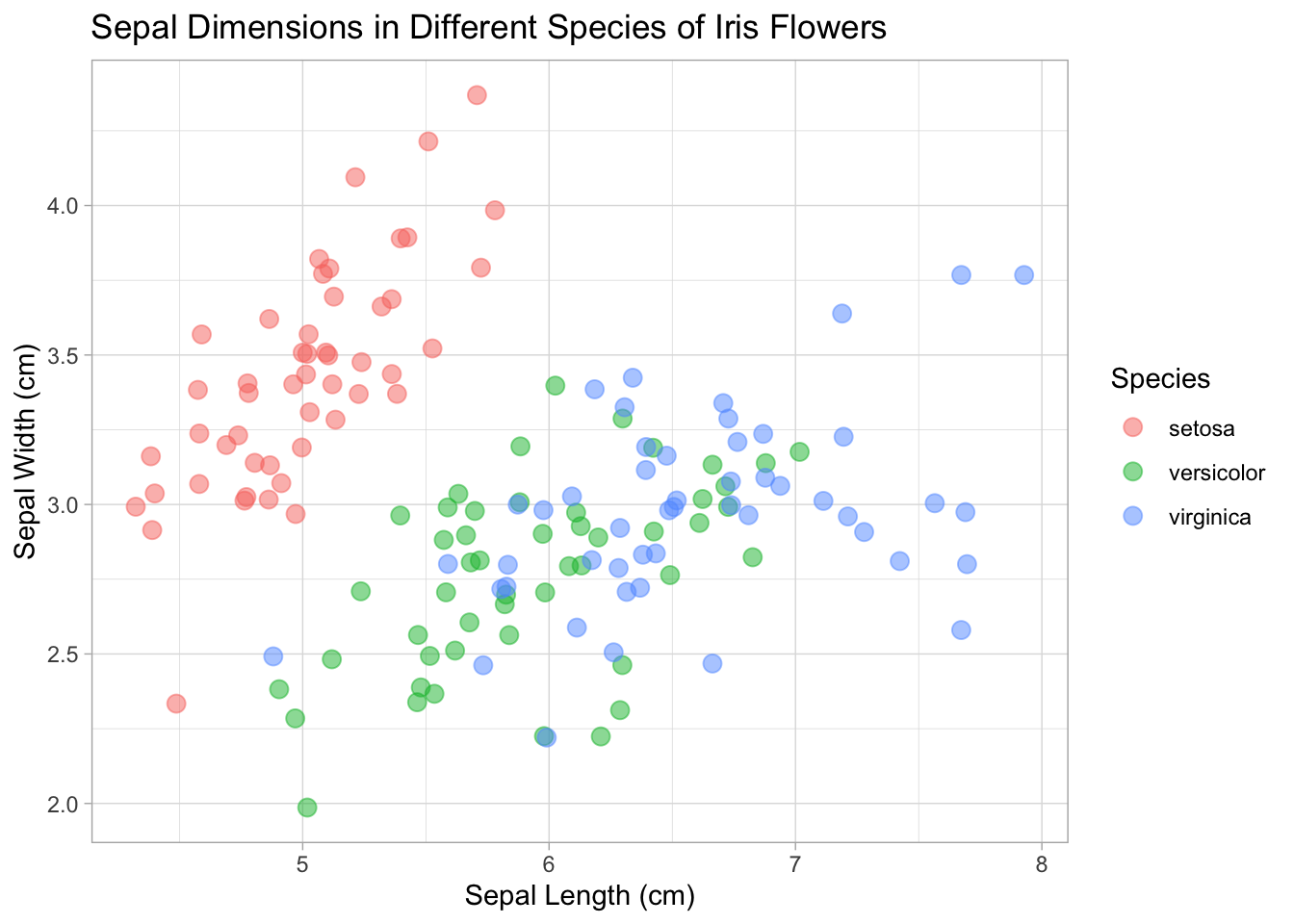
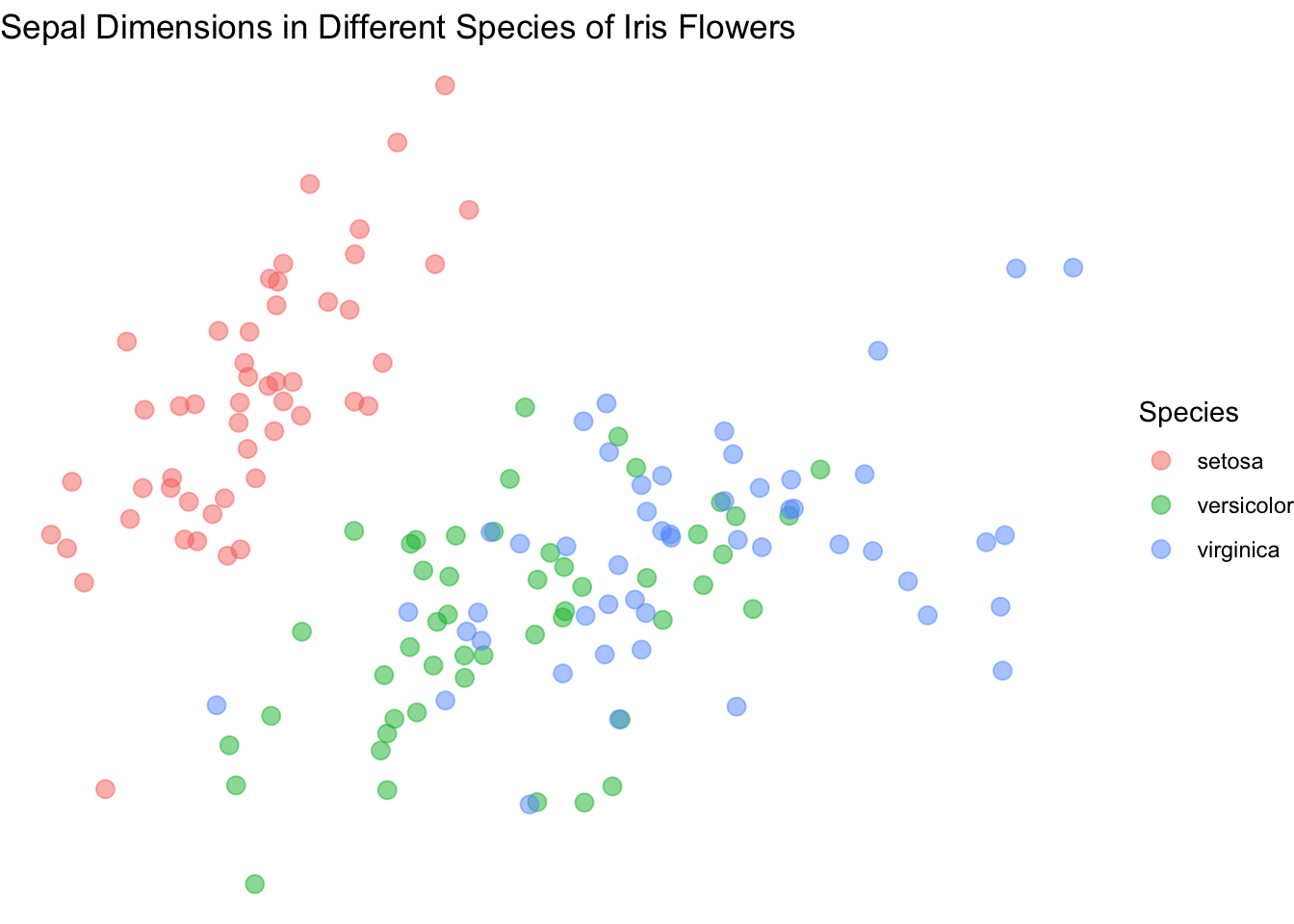
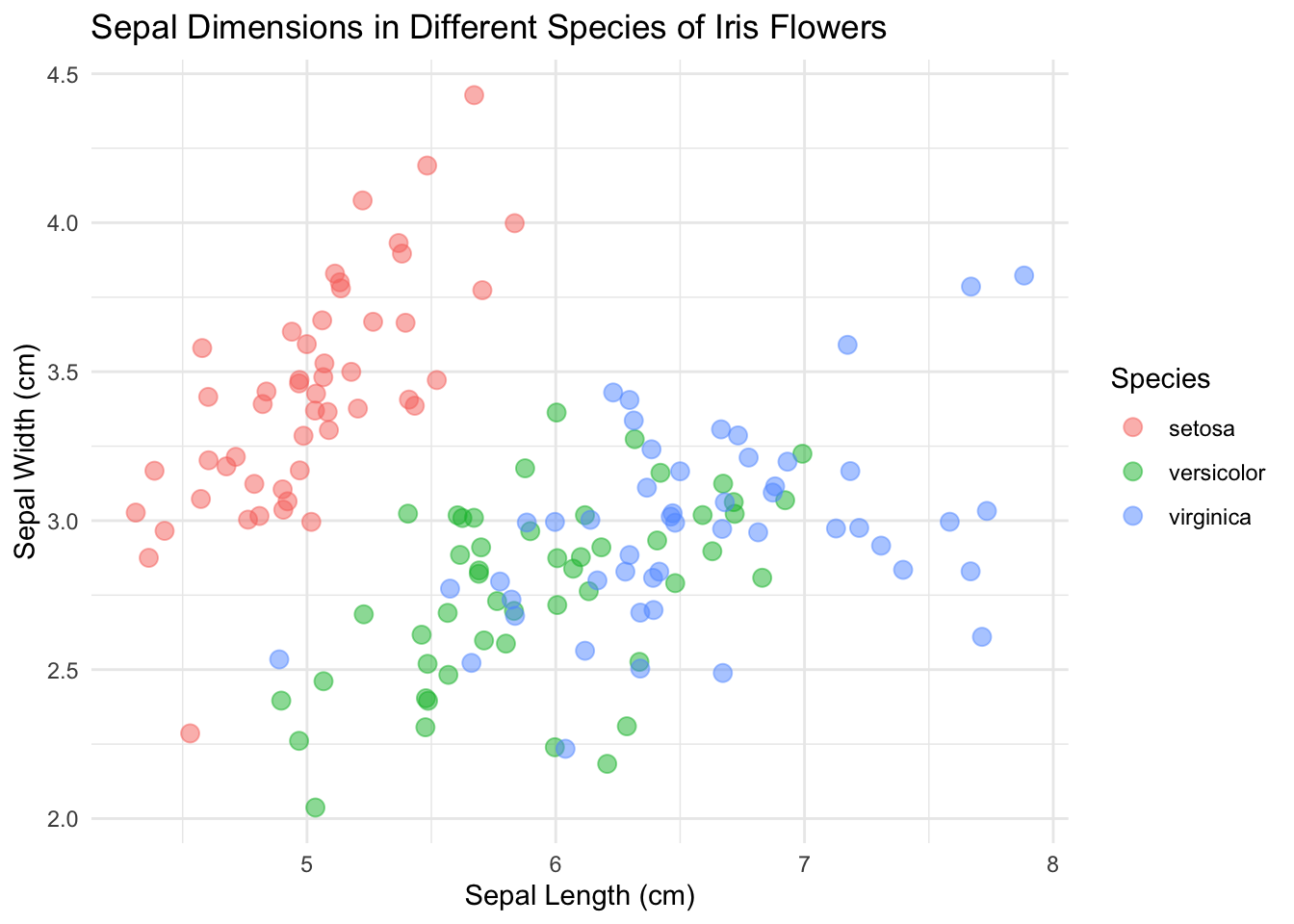
Cette fois je vais utilisé theme_minimal().
Nous y voilà ! Nous avons un scatterplot prêt à conquérir le monde !
13.10 Pour aller plus loin
Nous n’avons que toucher la surface de ggplot et toucher du doigt la grammaire des graphiques. Si vous souhaitez aller plus loin, je vous recommende hautement les cours de DataCamp Data Visualization with ggplot2 de Rick Scavetta. Ce cours est en 3 parties très denses, mais la première partie vaut vraiment le détour.
with