14 Chart: Parallel Coordinate Plots
 Ce chapitre était initialement une contribution à la communauté de aashnakanuga
Ce chapitre était initialement une contribution à la communauté de aashnakanuga
14.1 Vue d’ensemble
Cette secion couvre comment créer des graphiques à coordonnées parallèles statiques avec le package GGally.
Pour des graphiques à coordonnées parallèles interactifs, voir le package parcoords . Le package vignette donne des instructions pour l’utilisation de ce package.
14.2 tl;dr
Je veux un bel example! Pas demain, pas après le petit déjeuner, MAINTENANT!
Observons l’effet des différents attributs sur chaque coupe “Fair” de diamond du jeu de données “diamonds”:
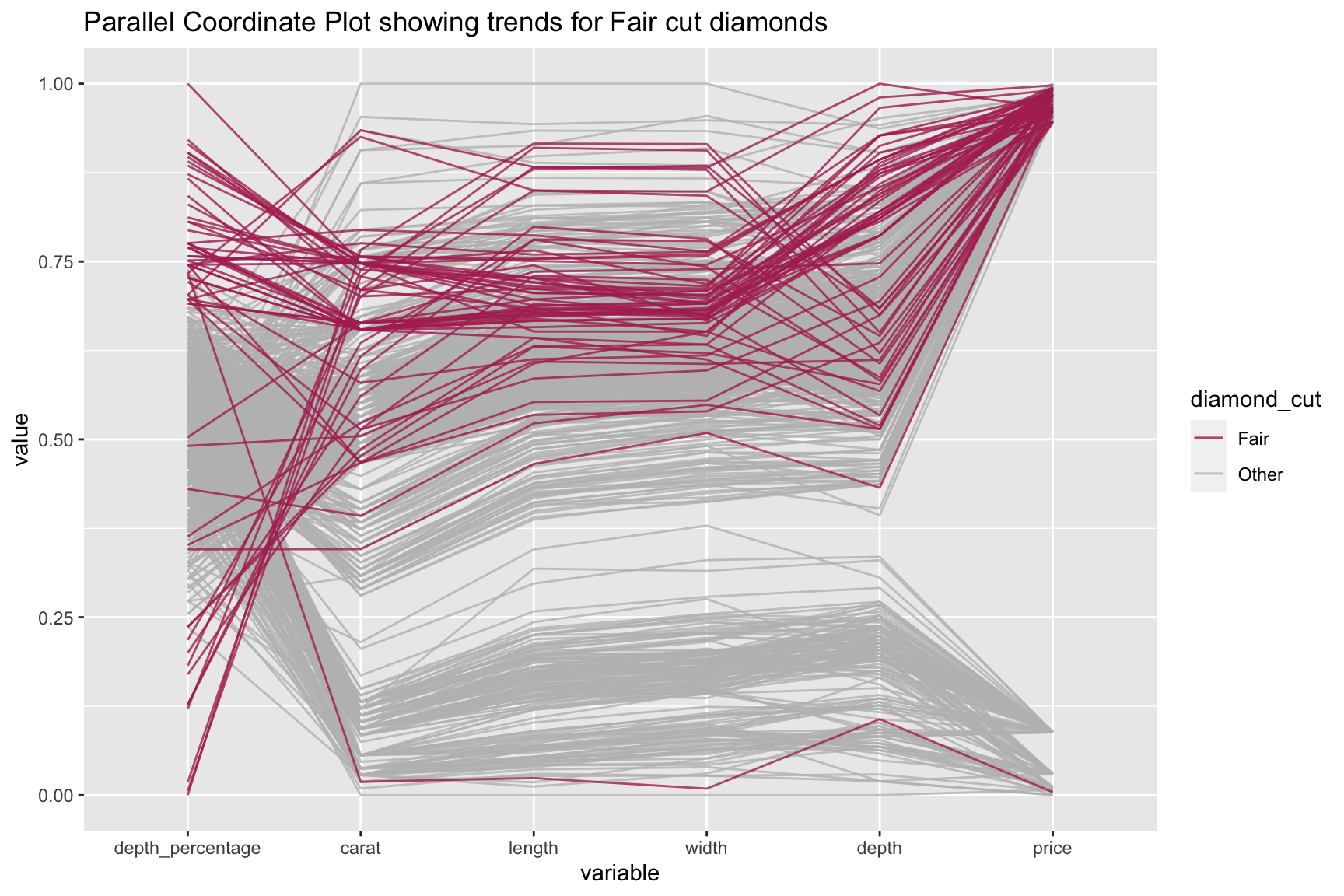
Et voici le code:
library(GGally)
library(dplyr)
#subset the data to get the first thousand cases
diamonds_subset <- subset(diamonds[1:1000,])
#rename the variables to understand what they signify
names(diamonds_subset)<-c("carat","cut","color","clarity","depth_percentage","table","price","length","width","depth")
#Create a new column to highlight the fair cut diamonds
ds_fair<-within(diamonds_subset, diamond_cut<-if_else(cut=="Fair", "Fair", "Other"))
#Create the graph
ggparcoord(ds_fair[order(ds_fair$diamond_cut, decreasing=TRUE),], columns=c(1,5,7:10),
groupColumn = "diamond_cut", alphaLines = 0.8, order=c(5,1,8,9,10,7),
title = "Parallel Coordinate Plot showing trends for Fair cut diamonds", scale = "uniminmax") +
scale_color_manual(values=c("maroon","gray"))Pour plus d’informations sur ce jeu de données, tapez ?diamonds dans la console.
14.3 Examples simples
Du calme! Trop compliqué! Beacoup plus facile, s’il-vous-plaît.
Utilisons le jeu de données “iris” pour cet exemple:
library(datasets)
library(GGally)
ggparcoord(iris, columns=1:4, title = "Parallel coordinate plot for Iris flowers")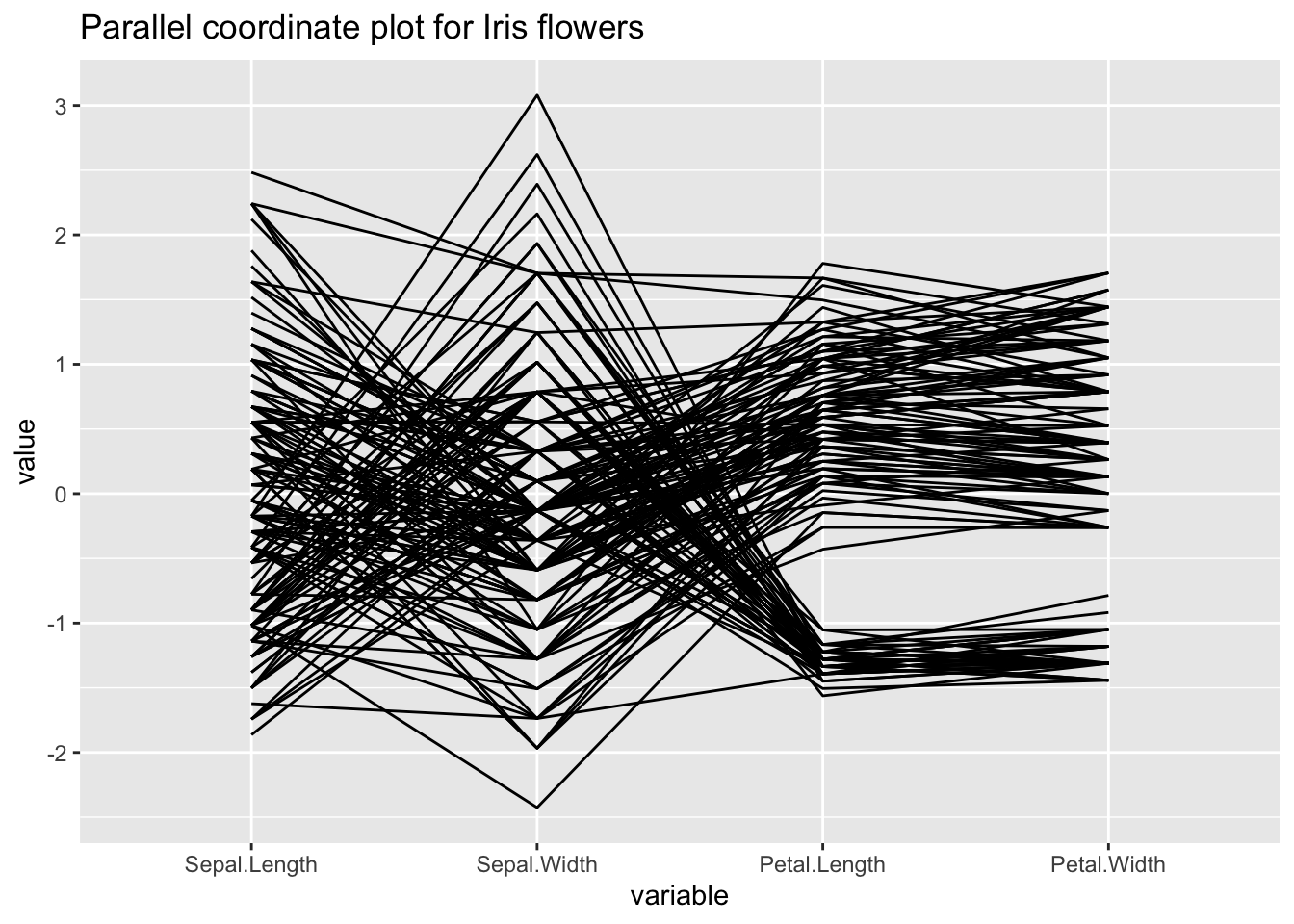
Pour plus d’informations sur ce jeu de données, tapez ?iris dans la console.
14.4 Theorie
Pour plus d’informations sur les graphiques à coordonnées parallèles et les données continues multivariées, regarder le Chapitre 6 du livre de cours.
14.5 Quand les utiliser
En général, les graphiques à coordonnées parallèles sont utilisés pour déduire des liens entre plusieurs variables continues - onles utilise en général pour detecter une tendance que nos données suivent, et les cas particuliers que sont les Generally, parallel coordinate plots are used to infer relationships between multiple continuous variables - we mostly use them to detect a general trend that our data follows, and also the specific cases that are valeurs aberrantes (outliers).
Veuillez garder à l’esprit que les graphiques à coordonnées parallèles ne sont pas idéaux quand il n’y a que des données catégoriques. Nous pouvons inclure quelques variables catégoriques de nos axes dans un souci de clustering, mais utiliser beaucoup de variables catégorique cause une saturation du graphique, ce qui le rend moins interprétable.
Nous utilisons aussi les graphiques à coordonnées parallèles pour identifier les tendances dans des clusters particuliers - pour illustrer chaque cluster dans une couleur différente, utiliser l’attribut groupColumn de ggparcoord(), specifiez votre colonne, et c’est parti!
Parfois, les graphiques à coordonnées parallèles sont utiles pour les séries temporelles - quand nous avons des informations enregistrées à des intervalles de temps réguliers. Chaque axe vertical sera desormais un point temporel et nous passerons cette colonne en attribut “column” pour ggparcoord.
14.6 Considerations
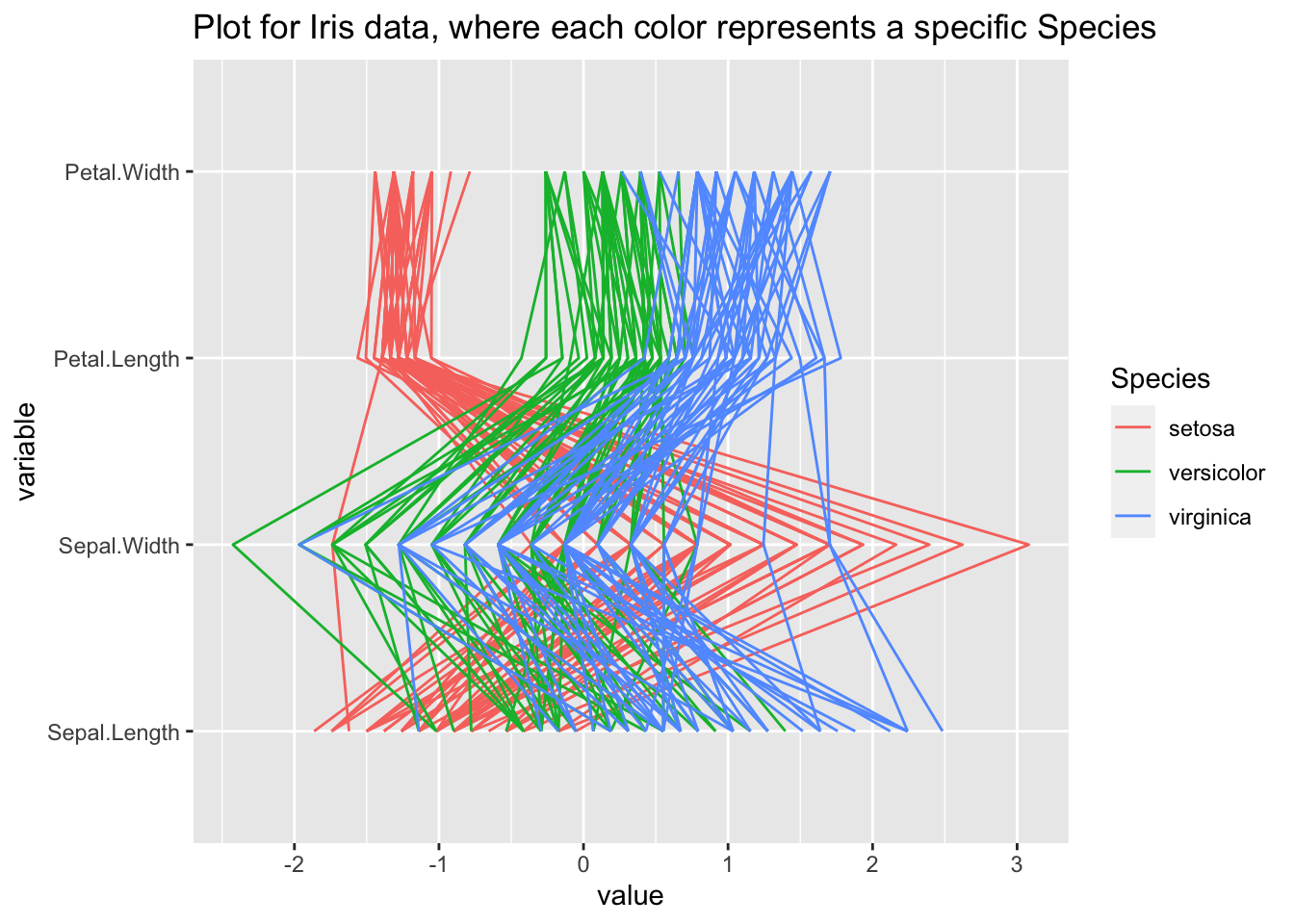
14.6.1 Quand utiliser le clustering?
En général, on utilise le clustering quand on veut observer un motif récurrent dans des données catégoriques avec des propriétés spécifiques. On divise les variables en clusters selon leur valeur spécifique pour une certaine variable catégorique. On peut également utiliser une variable continue; en la transformant en variable catégorique. Par exemple, en divisant les valeurs possibles selons deux cas: pour une variable continue taille: on divise en ceux dont la taille est supérieure à 150cm et ceux pour lesquels ça n’est pas le cas.
Regardons un exemple avec le dataset iris, en clusterisant la colonne “Species”:
library(GGally)
#highlight the clusters based on the Species column
graph<-ggparcoord(iris, columns=1:4, groupColumn = 5, title = "Plot for Iris data, where each color represents a specific Species")
graph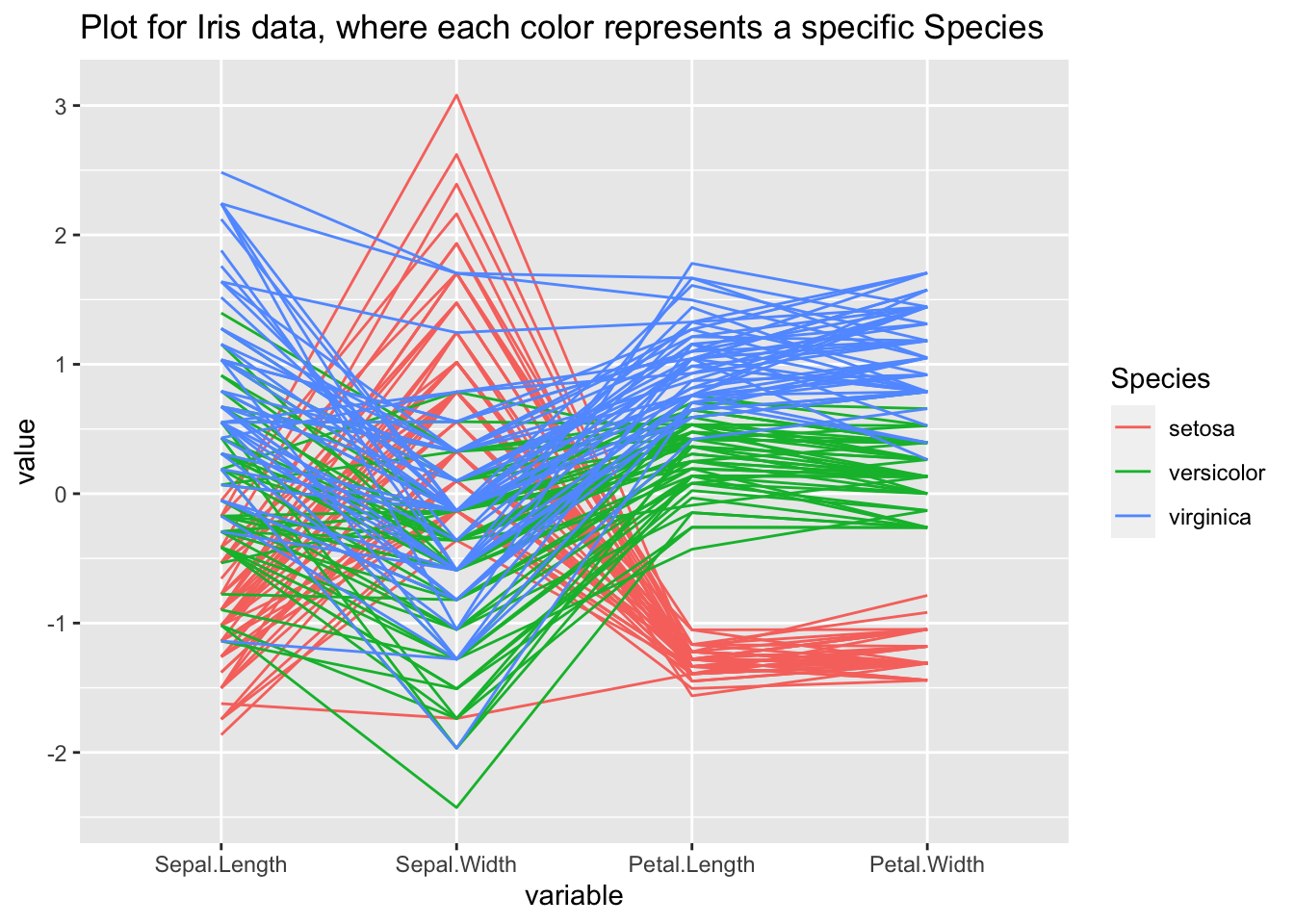
14.6.2 Choix du paramètre alpha
En pratique, les graphiques à coordonnées parallèles ne sont pas utiles pour des petits jeux de données. Il est plus probable que vos données soient constituées de milliers de cas différents, et il est parfois difficile d’interpréter un graphique à coordonnées parallèles quand autant de cas se recoupent. Pour résoudre ce problème, on définit le paramètre alphalines avec une valeur entre 0 et 1. Ce paramètre réduit l’opacité des lignes pour qu’on puisse mieux comprendre ce qui se passe quand beaucoup de cas se recoupent.
On utilise à nouveau le jeu de données iris, mais en réduisant le paramètre alpha à 0.5. Regardez comme il est beaucoup plus facile de suivre le cours de chaque cas:
library(ggplot2)
library(GGally)
#set the value of alpha to 0.5
ggparcoord(iris, columns=1:4, groupColumn = 5, alphaLines = 0.5, title = "Iris data with a lower alpha value")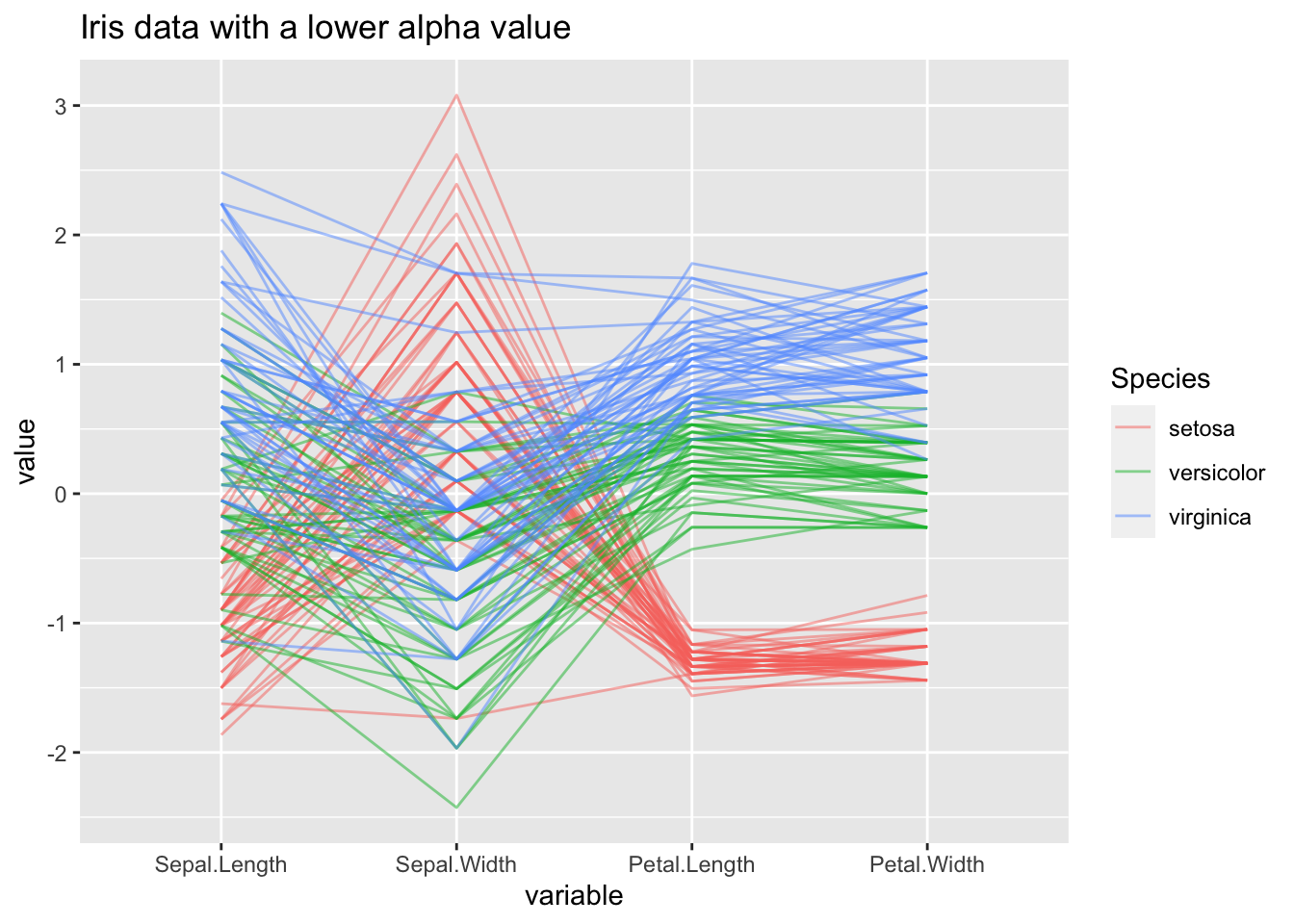
14.6.3 Scales
Quand on utilise ggparcoord(), on peut définir l’attribut scale, qui met à la même échelle toutes les variables pour qu’on puisse comparer leurs valeurs simplement.
Les différents types d’échelle sont:
- std: valeur par défaut, on soustrait la moyenne et on divise par l’écart-type
- robust: on soustrait la mediane et on devise par l’ecart absolu de la médiane (median absolute deviation)
- uniminmax: on met à l’échelle toutes les valeurs pour que le minimum soit à 0 et le maximum à 1
- globalminmax: pas de mise à l’échelle, on garde les valeurs d’origine
- center: On centre chaque variable selon sa valeur donnée par scaleSummary
- centerObs: on centre chaque variable selon sa valeur donnée par centerObsID
Créons un échantillon de données et observons comment les valeurs sur l’axe des y changent pour chaque échelle:
library(ggplot2)
library(GGally)
library(gridExtra)
#creating a sample dataset
df1<-data.frame(col1=c(11,4,7,4,3,8,5,7,9), col2=c(105,94,138,194,173,129,156,163,148))
#pay attention to the different values on the y-axis
g1<-ggparcoord(df1, columns=1:2, scale = "std", title = "Standard Scale")
g2<-ggparcoord(df1, columns=1:2, scale = "robust", title = "Robust Scale")
g3<-ggparcoord(df1, columns=1:2, scale = "uniminmax", title = "Uniminmax Scale")
g4<-ggparcoord(df1, columns=1:2, scale = "globalminmax", title = "Globalminmax Scale")
g5<-ggparcoord(df1, columns=1:2, scale = "center", scaleSummary = "mean", title = "Center Scale")
g6<-ggparcoord(df1, columns=1:2, scale = "centerObs", centerObsID = 4, title = "CenterObs Scale")
grid.arrange(g1, g2, g3, g4, g5, g6, nrow=2)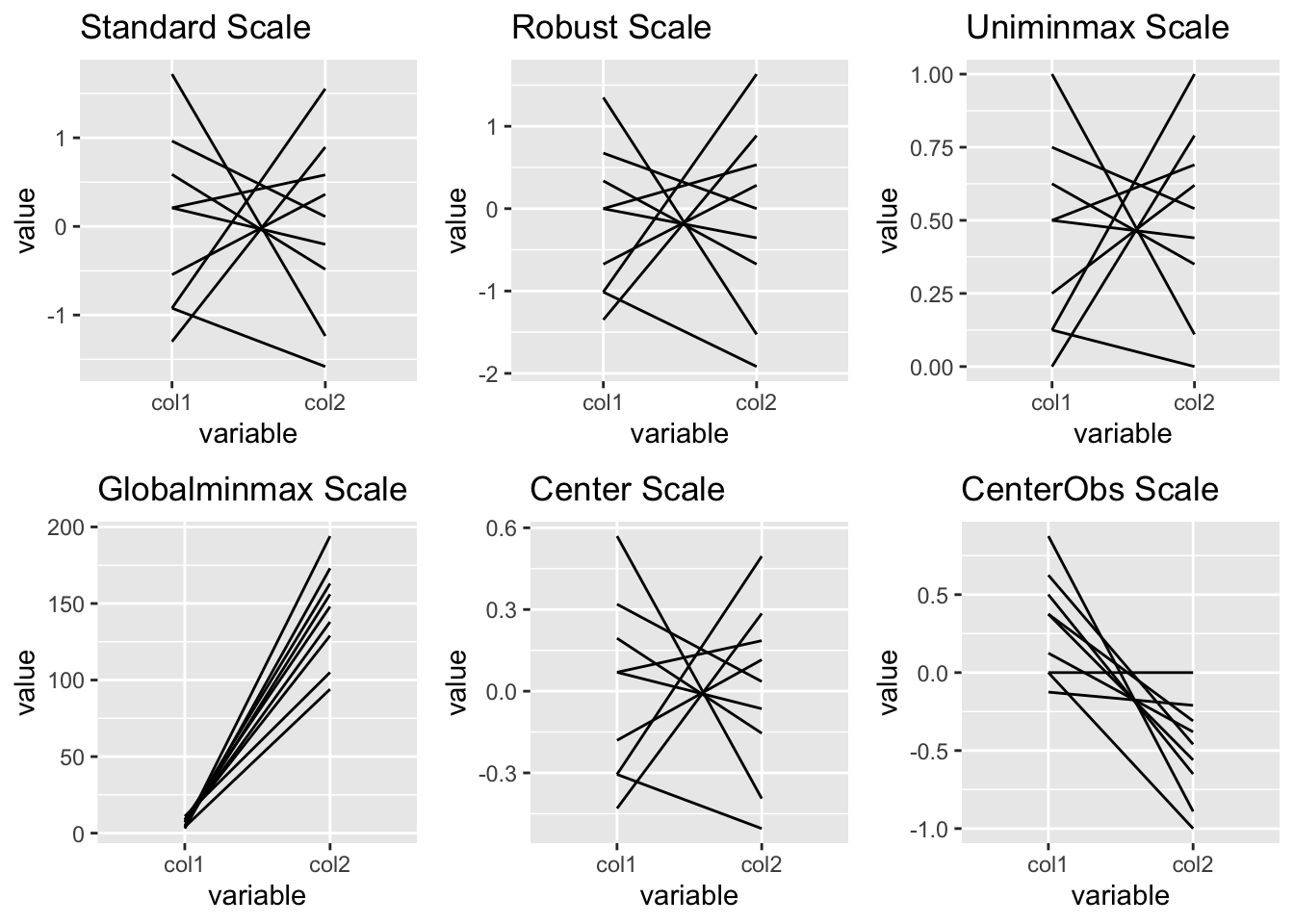
14.6.4 Ordre des variables
Le choix de l’ordre des variables sur l’axe des y dépend de l’application. Il peut être spécifié avec le paramètre order.
Les différents types d’ordre sont:
- default: l’ordre dans lequel nous ajoutons nos variables à l’attribut column
- given vector: on donne un vecteur contenant l’ordre dont on a besoin (cas le plus fréquent)
- anyClass: l’ordre basé sur la séparation d’une variable des autres (F-statistic - chaque variable v/s le reste)
- allClass: l’ordre basé sur la variation entre les classes (F-statistic - groupe column v/s le reste)
- skewness: l’ordre du plus au moins dévié (skewed)
- Outlying: l’orre basé sur la valeur de Outlying
14.7 Modifications
14.7.1 Permutation des coordonnées
C’est une bonne idée quand on a trop de variables et que leurs noms se chevauchent sur l’axe des x:
14.7.2 Faire appparaître des tendances
Voyons quelle tendance suit l’espèce Versicolor du jeu de données iris par rapport aux autres variables:
library(ggplot2)
library(GGally)
library(dplyr)
#get a new column that says "Yes" of the Species is versicolor.
ds_versi<-within(iris, versicolor<-if_else(Species=="versicolor", "Yes", "No"))
ggparcoord(ds_versi[order(ds_versi$versicolor),], columns = 1:4, groupColumn = "versicolor", title = "Highlighting trends of Versicolor species") +
scale_color_manual(values=c("gray","maroon"))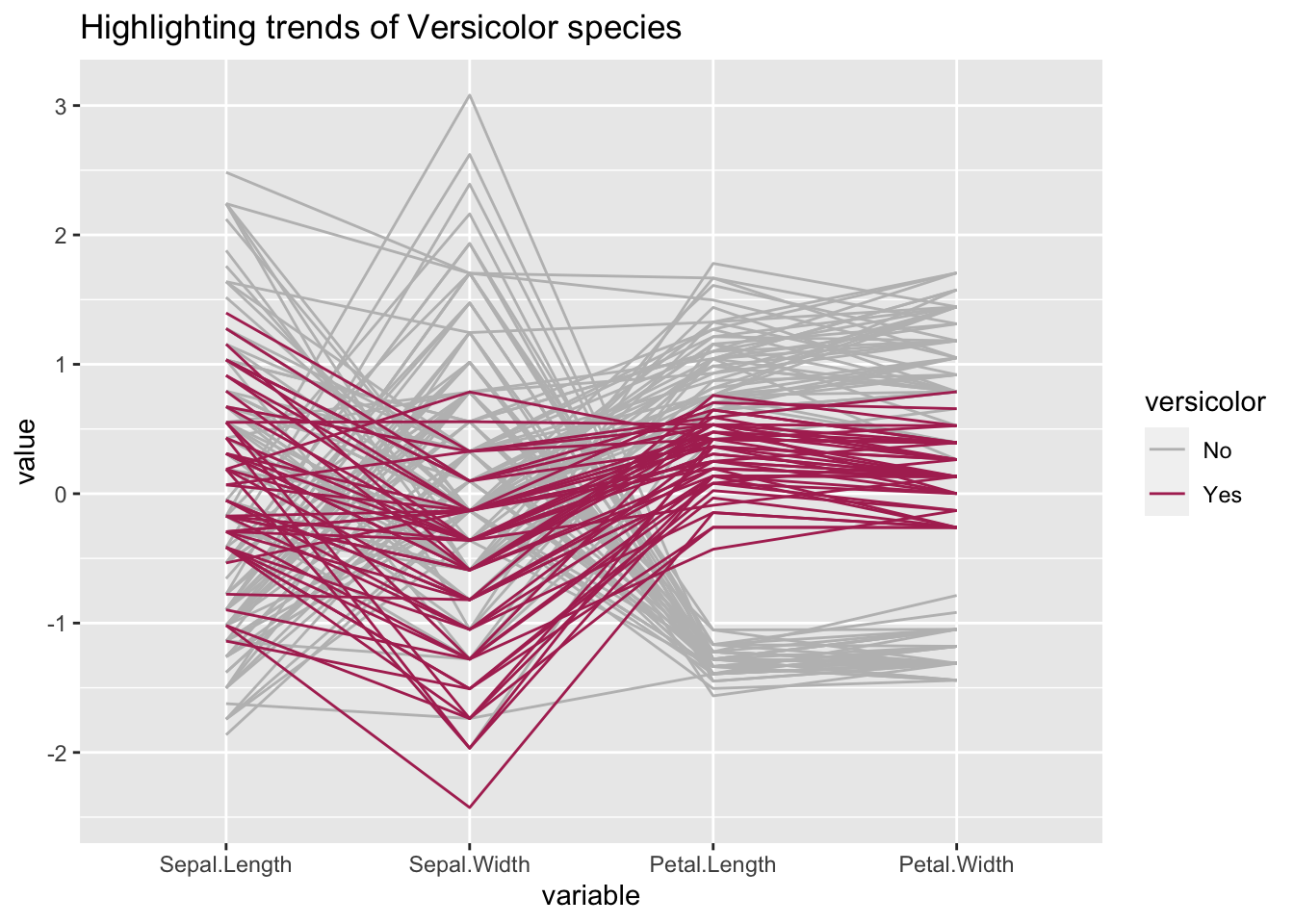
14.7.3 Utilisation de splines
En général, one utilise les splines quand on a une colonne dans laquelle beaucoup de valeurs se répètent, ce qui ajoute beaucoup de bruit. Les lignes de spline deviennent de plus en plus incurvées quand on choisit un facteur spline élevé, ce qui retire du bruit et rend l’observation de tendances plus facile. Il peut être défini en utilisant l’attribut splineFactor :
library(ggplot2)
library(GGally)
library(gridExtra)
#create a sample dataset
df2<-data.frame(col1=c(1:9), col2=c(11,11,14,15,15,15,17,18,18), col3=c(4,4,4,7,7,7,8,9,9), col4=c(3,3,3,4,6,6,6,8,8))
#plot without spline
g7<-ggparcoord(df2, columns = 1:4, scale = "globalminmax", title = "No Spline factor")
#plot with spline
g8<-ggparcoord(df2, columns = 1:4, scale = "globalminmax", splineFactor=10, title = "Spline factor set to 10")
grid.arrange(g7,g8)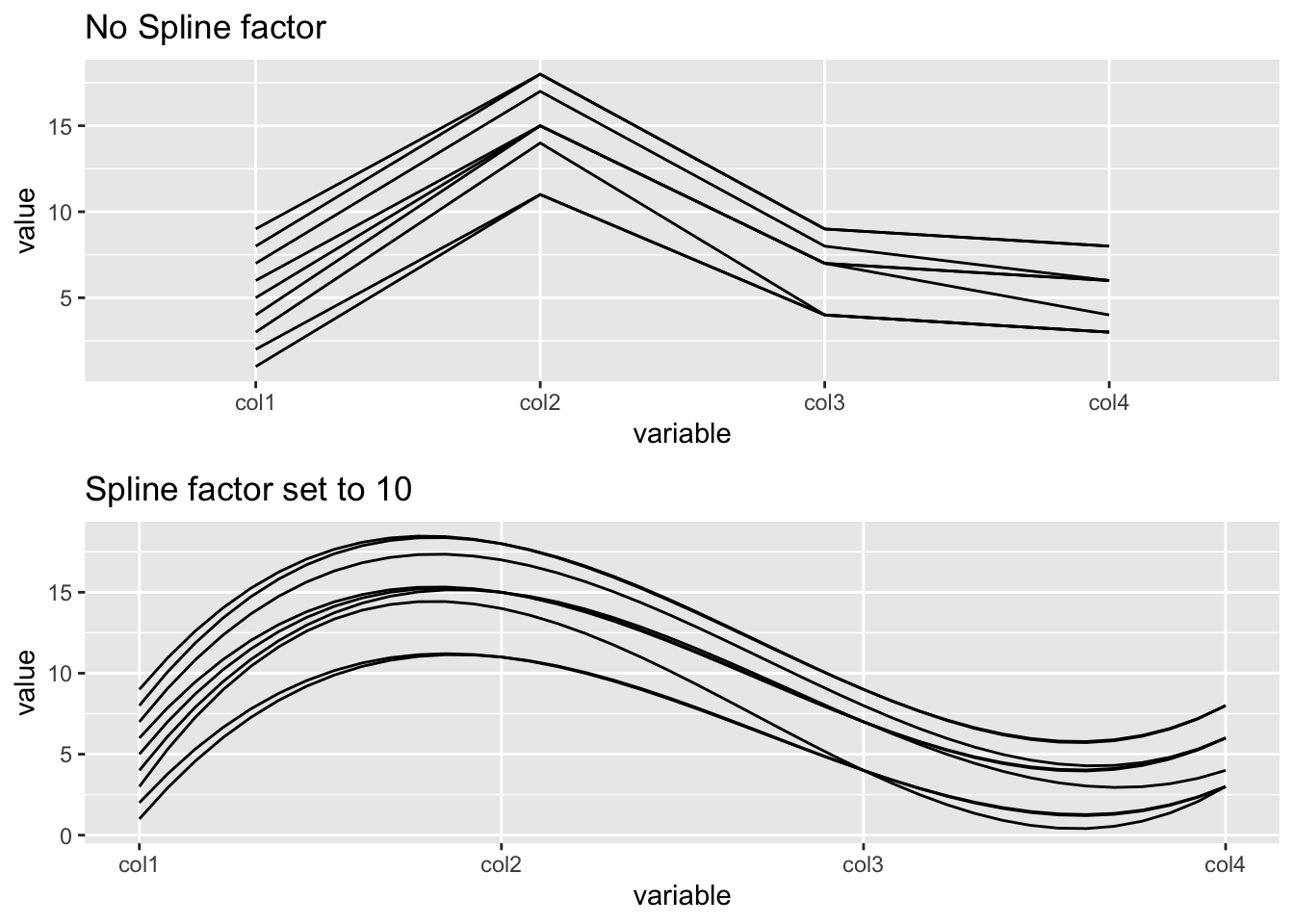
14.7.4 Ajout de boxplot au graphique
You can add boxplots to your graph, which can be useful for observing the trend of median values. Generally, they are added to data with a lot of variables - for example, if we plot time series data. Vous pouvez ajouter des boxplots à votre graphique. C’est utile pour observer la tendance de la médiane des valeurs. En général, on les ajoute aux données avec beaucoup de variables - par exemple, les séries temporelles.
14.8 Autres Packages
Il y a une multitude d’autres packages qui ont des fonctions pour créer des graphiques à coordonnées parallèles: [à faire: ajouter des liens]
parcoords::parcoords()– une bonne solution interactiveggplot2::geom_line()– n’est pas propre aux graphiques à coordonnées parallèles, mais sont faciles à créer avec le paramètregroup=.lattice::parallelplot()MASS::parcoord()
14.9 Ressources Externes
- Introduction to parallel coordinate plots: Très bonne ressource qui donne des détails pour chaque attribut et chaque valeur possible. Possède de bons exemples.
- How to create interactive parallel coordinate plots: explique bien comment utiliser plotly pour créer un diagramme à coordonnées parallèles interactif.
- Different methods to create parallel coordinate plots: Uniquement quand on a des variables categoriques.
with